

ゲーム用グラフィックボードのほとんどは単精度浮動小数点演算性能を重視しており、倍精度浮動小数点演算性能は気休め程度しか用意されていません。ゲームでは倍精度64bitほどの有効桁数はまったく不要で単精度32bitで十分だからです。
しかし金融分野では倍精度どころか4倍精度以上が必要なほど小数の精度(仮数部の桁数)が重要です。実測を伴う分野では測定誤差があるので有効数字の桁数分だけ仮数部の桁数があればいいですが、金融分野で扱う価格などのデータは測定誤差が無いため有効桁数が無限大であり非常に大きなビット数を用意した仮数部が必要です。
ここでは倍精度を重視したグラフィックボードを掲載しています。
64bit幅のFMA演算機をフル活用したときの倍精度浮動小数点演算FLOPS(Floating-Point Operations Per Second)値で比較しています。
単精度性能があれば十分なゲーム用はこちらに別掲しています。
- GPUには倍精度FLOPS性能と単精度FLOPS性能がある
- TeslaとQuadroの違い
- QuadroとGeForceの違い
- 1位: NVIDIA Quadro GV100 【8.330240TFlops】
- 2位: NVIDIA Tesla V100【8.330240TFlops】
- 3位: AMD Radeon Instinct MI60【7.3TFlops】
- 4位: AMD Radeon Instinct MI50【6.7TFlops】
- 5位: NVIDIA Quadro GP100【5.304TFlops】
- 6位: AMD Radeon VII【3.4585TFlops】
- 7位: NVIDIA Tesla K80【1.87TFlops】
- 8位: NVIDIA Quadro RTX 8000【0.5098TFlops】
- 9位: NVIDIA Quadro RTX 6000【0.5098TFlops】
- 10位: NVIDIA Quadro P6000【0.375TFlops】
- 11位: NVIDIA Quadro RTX 5000【0.3485TFLops】
- 12位: NVIDIA Tesla T4【0.2544TFlops】
- 13位: NVIDIA Quadro RTX 4000【0.222TFlops】
- 14位: NVIDIA Quadro M6000【0.19TFlops】
- 15位: NVIDIA Tesla P4【0.17TFlops】
- 16位: NVIDIA Quadro M2000【0.0566TFlops】
- Turing世代アーキテクチャにおける倍精度浮動小数点演算
- CUDA Coreは倍精度(FP64)演算器を含まない
- 倍精度に関しては最新の世代ほど高性能とは限らない
GPUには倍精度FLOPS性能と単精度FLOPS性能がある
Flopsとは1秒間あたりにできる小数演算の回数です。10TFlopsだとつまり1秒間に10兆回も小数の計算をできる能力があることになります。
なぜ小数かというと整数演算は非常に短時間でできて回路の実装が容易であるため性能を競う対象として不適格だからです。また整数系のアプリケーションはデータレベル並列性が低い傾向にあることにも起因しています。整数演算を並列化するハードウェアを計算機側で用意してあげたところで使い切れないためです。
一方で小数演算を扱うアプリケーションはデータレベル並列性が高く存在することが多く、コンピュータ・ハードウェアとして小数演算の並列化支援をして高速化を図ることはメリットがあります。並列化しやすいということはFLOPSを向上させやすいということであり、整数演算よりも伸びしろが大きい浮動小数点演算で性能のスケールを競争しているのがハイパフォーマンスコンピューティング(HPC)の分野です。
整数よりも演算に時間がかかり応用分野が広い小数演算の回数でコンピュータの速さを競うのがスパコンでもパソコンでも同じです。
小数は演算に時間がかかります。小数の中でも乗算(かけ算)と除算(割り算)の時間がかかり、特に除算についてはとてつもなく時間がかかります(一方向性)。1秒間でいかに多く小数の計算できるかがグラボの性能を決定します。
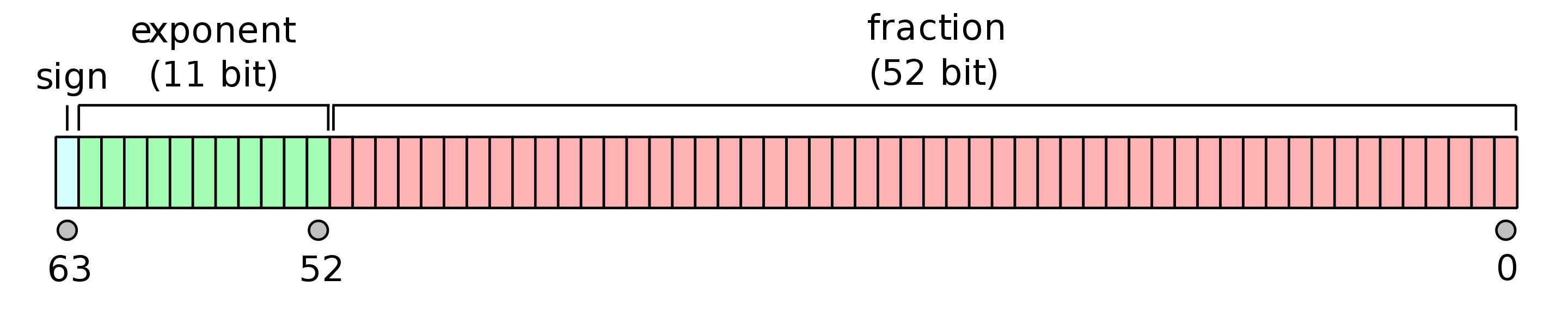
倍精度は64bitで小数を表現 単精度は32bitで小数を表現
ゲームで使われる単精度小数というのは32bitで小数を表現したものです。なぜ32bitが「単」かというと、従来は32bitを1ワード長としたコンピュータアーキテクチャが一般的だったからです。現在は64bitが主流なので64bitを倍精度とするのは違和感がありますが、今でもInt型が32bitであるためそれを基準にして単なのか倍なのか区別しています。
例えば単精度だと以下のように小数を表現しています。

fraction(仮数部)という部分が非常に重要です。ここが小数の精度を決定しています。
仮数部では頭の1があるものとして正規化して表現するため、実際の仮数部は1+23=24bit分の精度があります。exponentは指数部のことで、2^{exponent}として数の絶対値を決定する部分ですが、ここは小数の精度には影響せず単なる「数の大きさ」の振れ幅を決めるだけです。小数の精度は仮数部の桁数が全てであり、この精度をより高く確保するために倍精度・4倍精度・8倍精度が定義されています。
一方で倍精度は以下のようになっています。
仮数部が52bitもあります。同様に頭1bit目は”1″になるよう正規化されてからこのfractionに代入されるため、実際は1+52=53bitの仮数部があります。このようにしてみると単精度の24bitよりも倍精度の53bitのほうが2.2倍の仮数部の長さがあることがわかります。つまり倍精度は単精度よりも2.2倍の長さの小数精度を表現できるということです。
32bitや64bitというのは全体の長さでしかありません。仮数部に着目すると、倍精度浮動小数点数は単精度浮動小数点数の2.2倍もの精度をもっていることは重要です。
1秒間に倍精度の小数演算を実行できる回数が倍精度FLOPS
そうなるとFLOPSにはいくつか定義があります。上述した単精度の小数を実行できる回数のFLOPSなのか、倍精度の小数を実行できる回数のFLOPSなのかどうかです。
GPUには単精度用の演算器と、倍精度用の演算器をそれぞれ別々に用意するのが主流です。PascalやVoltaまではそのようになっていました。その場合はそれぞれの演算器の個数が単精度FLOPSと倍精度FLOPSを決定します。
一方でTuringアーキテクチャでは倍精度演算器を搭載していません。単精度演算器を使って擬似的に倍精度の演算をエミュレーションしています。そうなると倍精度のFLOPS値はかなり低くなります。
当然ながら128bitの4倍精度の浮動小数点数のFLOPSも定義できます。このようにFLOPS値は1つではなく、浮動小数点数の精度によって大きく変化するので、どの小数精度におけるFLOPS値なのか区別することが重要です。今回この記事では倍精度に主眼を置いています。
TeslaとQuadroの違い
Teslaは基本的に、Quadroのグラフィック出力機能を削ったものです。
グラフィック出力を有したQuadro GV100は、グラフィック出力の無いTesla V100として展開されています。どちらも使っているチップは同じでブーストクロックも同じです。クロックもメモリサイズも揃えてラインナップされています。
TeslaとQuadro間の大きな違いはメモリのエラー検出・訂正の機能がTeslaには存在し、Quadroには存在しないことです。これはIntel XeonとIntel Coreの違いと同じで、XeonはRegistered,ECCメモリに対応していますがIntel CoreはUnbuffered,Non-ECCです。これと同じ関係がTeslaとQuadroにも当てはまります。
エラー検出・エラー訂正といっても、bitの誤り数があまりに多く訂正も検出もできなくなることは確率的にはゼロではありませんが、通常の使用範囲内ならそのようなことは確率的に非常に稀であり十分に機能します。
なぜQuadroにはメモリのエラー検出・エラー訂正が無いかというと、Quadroはグラフィック処理向けだからです。グラフィック処理とは、各オブジェクトの位置座標と光源とカメラの位置座標を元にして、各ピクセルでどのような色(RGB)になるかを計算する処理です。
たとえ途中でメモリエラーでbitの誤りが発生したとしても、それは極一部のピクセルの色が正確でないといった影響しかありません。4K(3840×2160)=8,294,400ピクセルといった膨大のピクセル数の一部の色が誤るだけです。しかもグラフィックでは1秒間あたりに60回もフレームが切り替わるわけで、一瞬そのような誤りが発生したところで一部の人が気づいて気にするくらいです。そのようなメモリエラーが発生してもグラフィック用途では壊滅的な影響はないわけです。
しかしTeslaは科学技術計算向けです。Teslaで計算しているのが金融工学で扱うデリバティブのプライシング(価格決定)である場合、その算出された時価やリスク値(Greeks)が異なってしまったら金融商品価値を誤って認識してしまい、デリバティブを保有している企業の金融商品時価を間違えてしまうことで損益計算書や貸借対照表が誤ることになります。これはその企業の財務諸表を正確に把握したい投資家の損失に繋がる可能性があります。またリスク値(Greeks)が異なればヘッジトレーダーが判断を誤るといった甚大な経済的被害が発生します。しかも金融分野の計算というのは、一度数値が誤るとその数値に対して何度も演算を繰り返すため1回のエラーがずっとその後も尾を引きます。このような理由から、絶対に数値の誤りを出したくない計算分野ではTeslaを用います。
またGeForceにも当然メモリエラー検出・訂正機能は付いていません。メモリエラーが発生して、表示すべきグラフィック表示が誤ったことでゲーマーが操作を誤り、TwitchやYoutubeで配信中にFPSゲームで負けたとしても経済的打撃は大したことがないからです。
QuadroとGeForceの違い
Quadroはゲーム向けではないと思っている人が多いですが、Quadroは普通にゲーム用でも使えます。単にゲームではオーバースペックなため対費用効果でQuadroでは割に合わないというだけであり、資金面を全く気にしないのならQuadroでもゲームは普通にできます。
Quadro(Tesla)はクロックが低く1コアあたりの性能が弱い
ゲームのグラフィック処理ではGPUの1コアあたりのクロックの高さがフレームレートの高さに直結するのでクロックが高く設定してあります。Referenceモデルでの時点でもGeForceのクロックは高く、ASUS等が出しているオリジナルファンモデルだとファクトリーオーバークロックされているのでさらにクロックが高くなります。
これはXeonも同じですが、アプリケーション内部に存在する並列性が高い分野では1コアあたりのクロックの高さよりもコア数の多さのほうが重要です。QuadroやTeslaもそのような分野と親和的です。
しかしゲームのような分野は、XeonよりもIntel Coreのような1コアあたりの性能が高いCPUのほうがフレームレート性能が上がるのと同じで、GPUでも1コアあたりのクロック数が高いGeForceのほうが高速です。
そういった意味で、AMD Radeonはコア数が多いかわりにクロックが低いGPUなので、ゲーム分野ではAMD Radeonは常にNVIDIA GeForceの後塵を拝しています。しかし並列性が高い用途だったらAMD Radeonのほうが優秀です。
Quadroは倍精度が強い場合も弱い場合もある GeForceは常に倍精度が弱い
また倍精度浮動小数点演算器の数がGeForceよりも「多い場合もある」のがQuadroです。しかし最近はGeForceでもQuadroでも倍精度演算器の数が同数のことがよくあります。
ゲーム用途ではグラボの単精度浮動小数点演算の能力が大変重要です。「倍精度」浮動小数点演算性能はゲームにおいては重要ではありません。
国土交通分野などのインフラの設計などにおいては小数演算の誤差が出ると建造物の崩壊に繋がり人命にかかわります。だからそのような分野では最低でも倍精度、場合によっては4倍精度以上を使ったり、究極的には浮動小数点演算を使わずに整数に直してから擬似的に小数演算を実行し誤差を小さくします。整数に直してしまえば表現誤差も無いし、数の絶対値が大きく違うもの同士を加減したときの情報落ちもないし、非常に値が近いもの同士を減算したときの桁落ちもないからです。
一方でゲームは所詮ゲームなので、最終的に液晶ディスプレイに映ったものを人間が視覚で認識すればそれで全て完結します。ゲーム上での物理描画の位置座標に多少の小数誤差があっても何の問題もないからです。FPSゲームの当たり判定のための座標表現も、倍精度は全く必要なく単精度で十分です。
搭載されているチップの設計は同じでも、より品質の高いチップを選んでいる
例えばTITAN RTXでもQuadro RTX 8000でも同じチップTU102を使っています。有効化されているコア数も同じです。
両者で使われるチップの違いとしては、同じクロック周波数で動作させても、より消費電力が低く安定しているものがQuadroに使われます。つまりチップの選別を実施しています。
搭載メモリ容量がQuadroのほうが大きい傾向
TITAN RTXは24GBのVRAMを搭載していますが、Quadro RTX 8000は48GBも搭載しています。
TITAN RTXですら「GeForce RTX 2080TiのVRAM11GBより大きい」と言われていますが、QuadroからしたらTITAN RTXのメモリ容量でもしょぼいわけです。
なぜならゲーム用だとVRAMにデータを置いてそれに対して繰り返し処理をするなんて用途はありません。CPUからオブジェクトや光源、カメラの位置のベクトル(座標)を受け取ったら、ディスプレイの各ピクセルの色がどうなるかRGBを決定するのがGPUの仕事です。
RGBを算出したらそれをディスプレイに送ってGPUの仕事は終わりです。再利用できる座標はVRAMに保存されますが、基本的にはどんどん捨てていってしまってかまわないデータばかりなのでゲーム用のGeForceではVRAM容量は少なくてOKです。
しかしQuadroの用途では繰り返し何度も何度も同じデータに対して処理を実行します。科学技術計算ならなおさらです。RAMからVRAMから転送し(APIで明示的に命令を書く)、VRAM上のデータに対してGPUは演算を実行します。そして演算が完了したら計算結果をVRAMからRAMへデータを持ってきてCPUが触れるようにします。このような用途だとQuadroのようにVRAMは大容量が要求されます。
QuadroとTeslaはNVIDIAが生産する製品のみ GeForceのように「オリジナルファンモデル」は存在しない
Quadroは国内正規代理店こそエルザジャパンだったり菱洋エレクトロだったりですが、生産に関して責任を負っているのはNVIDIAです。
GeForceではNVIDIAが提供するのはチップであり、ヒートシンク等や電源回路の搭載はASUS,MSI,ZOTACといったメーカが生産に責任を負っています。
一方でQuadroはNVIDIAから出荷された時点でどの代理店経由から買おうとも品質は同じです。Quadroの高品質を担保しているのがNVIDIAであり、「壊れたら困る」といった信頼性が高い用途でも使えるようにQuadroは設計・実装されています。ASUS製や玄人志向製で品質がバラバラのGeForceとは決定的に異なります。
Quadroの真骨頂はOpenGLに最適化されたドライバの提供
「Quadroの強みはOpenGLに最適化されたパフォーマンス」と言われますが、半分合っていて半分間違っています。QuadroでもGeForceでもハードウェア的にはOpenGLで性能が出るようになっています。しかしGeForceではドライバであえてOpenGL向けのパフォーマンスに制限をかけています。良い方向にみれば「QuadroはOpenGLで高速」ですが、悪く見れば「GeForceでも同じようにOpenGLを高速化できるのにNVIDIAが出し惜しみしてる」ということになります。これがNVIDIAが商売上の理由で計算性能を制限する「悪いところ」です。
GeForceもQuadroもハードウェアとしては同じです。搭載しているチップが同じだからです。しかしドライバでNVIDIAは「制限」しています。つまりリミッターです。AMDはそのようなことはしないので、その点はAMDはNVIDIAよりいい仕事をしています。
特に大学の研究室ではできるだけ安く計算資源を獲得することが要求されているので、できるだけGeForceで揃えようとします。
大学の研究室では信頼性なんてどうでもよく、とにかく高い演算性能が出ればGeForceでも十分です。民間企業と異なり製品としての付加価値を大学の研究室は生み出していないためまず歳入予算に上限があります。一般会計予算が歳入源になっている国立大学法人なら尚更です。その範囲内で歳出予算を決めるしかありません。付加価値を大きく生み出す見込みがあるならば歳入予算を大幅に上回る歳出予算があり得る民間企業とは根本的に異なる部分です。
そのかわり失敗しても民間企業のように経済的打撃がないので、故障率が高くてもGeForceで問題ありません。たとえGeForceが故障してデータが取れなくなり論文提出が間に合わなくても、被害は博士課程在籍者が留年することくらいであり、修士以下の学生はデータの取得に失敗してもなんだかんだ東大でも卒業・修了できちゃうのでほぼ被害はありません。
だからもしGeForceでもQuadroと同レベルのパフォーマンスが出るOpenGLのドライバがでたら、大多数の人がGeForceを選択するでしょう。そうなるとNVIDIAが儲からないためわざとリミッターを付けているわけです。
また大学等ではOpenGLに依存した研究が多いのも完全にQuadro脱却ができない原因でもあります。
DirectXやC#のようなMS製品は研究の実装で好まれません。コンピュータサイエンス分野の研究は理論的な設計だけはダメで、かならず「実装」して「評価」します。その実装に好まれて使われるのがC++,Java等のオープンなもので、OpenGLやOpenMPも同様です。プロプライエタリなもので実装することは嫌われます。
大学にもコンピュータ・グラフィクスを主軸に据えた研究室は大量にあります。彼らはOpenGL屋です。そういったニーズがある限り、GeForce向けにOpenGLに最適化されたドライバをNVIDIAが用意するとは考えづらいです。
そういったことで足元をみているのがNVIDIAなので、そこはAMDやIntelのdGPUでNVIDIA岩盤を崩して欲しいところです。
1位: NVIDIA Quadro GV100 【8.330240TFlops】
CUDA Core5,120、Streaming Multiprocesser80基、
2018年3月にリリースされたTSMC 12nmプロセスで製造され815平方mmのチップ(ダイ)面積を持つGPUです。
このGV100はCUDA Core5,120コアですが、倍精度の性能をみるならCUDA Core

微細化とチップ面積の増加によるコア数の増加で達成された+42.86%の性能向上に加えて、PascalアーキテクチャをVoltaアーキテクチャに置き換えたことによるアーキテクチャの改良の両輪で+48%の性能向上を達成しています。
・NVIDIA Quadro GV100 EQGV100-32GER
Displayport×4、メモリ32GB










・PNY NVIDIA Quadro GV100













・ELSA NVIDIA Quadro GV100 NVQGV100-32GHBM2
2位: NVIDIA Tesla V100【8.330240TFlops】
Tesla V100はディスプレイ出力のあるGV100のアクセラレータ版です。単にコプロセッサとしての演算器が欲しいのならこちらで十分です。
・NVIDIA Tesla V100








・Spermicro NVIDIA Telsa V100






・HP NVIDIA Tesla V100 16GB ETSV100-16GER




・PNY NVIDIA Tesla V100 TCSV100MPCIE-PB






3位: AMD Radeon Instinct MI60【7.3TFlops】
VRAM32GB, TSMC7nmプロセス、Boostクロック1,800MHz
NVIDIAのStreaming Multiprocessorに相当するCUは64基、CUDA Coreに相当するSPは4,096個搭載しています。
倍精度用演算器は2,048個搭載しています。
このRadeon Instinctが評価できるのは、倍精度向けの演算器の数が優遇されており、単精度のFLOPS値の1/2も確保できていることです。
4位: AMD Radeon Instinct MI50【6.7TFlops】
VRAM16GB、TSMC7nmプロセス、Boostクロック1,746MHz
NVIDIAのSMに相当するCUは60基、CUDA Coreに相当するSPが3,840個搭載。MI60のCUのうち4基を無効化して歩留まりを向上させ低価格にして提供されているのがMI50です。動作クロックも若干低くなっています。倍精度演算器は1,920も搭載されており倍精度6.7TFlopsを実現しています。MI50もMI60と同じで単精度FLOPSの1/2も倍精度FLOPSを実現しています。対費用効果でみるとGV100よりMI60やMI50のほうが優秀です。
5位: NVIDIA Quadro GP100【5.304TFlops】
2017年2月にPascalアーキテクチャにおけるフラッグシップモデルが発表されました。
16nmプロセスで製造されるチップを用いたDiscrete GPUとしては最高峰です。
Streaming Multiprocessorは56コア有効化されています。SM1基あたりの内部ブロック図は以下の通りです。
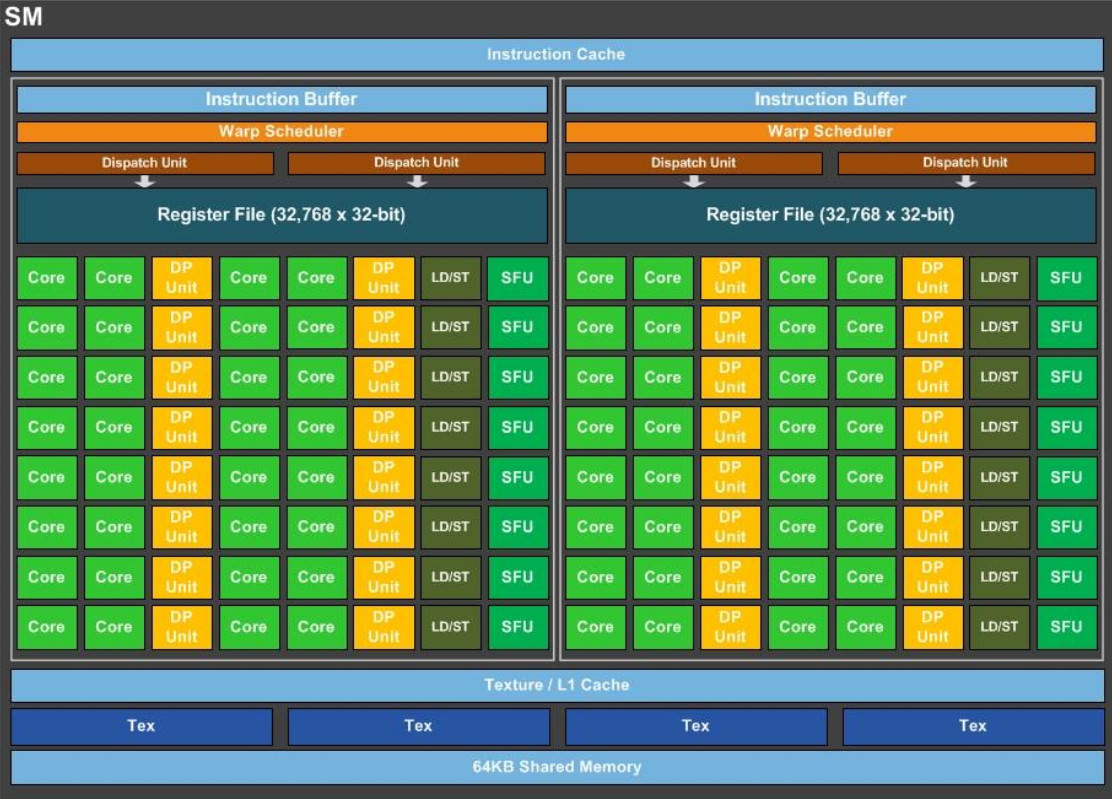
SM1基あたり2つのブロックがあり、1つのブロックには倍精度演算器が16個あります。
つまりSM56基×2ブロック×演算器16=1,792個の倍精度浮動小数点演算器を搭載しています。
このQuadro GP100は「単精度」浮動小数点演算が10.608640TFlopsありますが、これはGTX1080Tiの「単精度」浮動小数点数演算能力とほぼ同じです。1080Tiも10TFlopsあります。これはQuadro GP100も1080Tiも単精度CUDA Coreが同数である3,584コアということからもわかります。
では1080tiとこのQuadro GP100は何が違うのかというと、「倍精度」浮動小数点演算の性能が決定的に異なります。Quadro GP100は倍精度用の演算器は先程計算して示したように1,792コアもあります。一方で1080Tiとの明確な違いでありQuadro GP100の特徴を決定づけています。
このQuadro GP100の「倍精度」浮動小数点演算能力は5TFlopsもあり、1080Tiがたったの0.36TFlopsしかないのとは大違いです。
5TFlopsと言っても実感がわかないでしょうが、日本国内にあるスパコン「京コンピュータ」は倍精度で10,000TFlops=1京Flopsの性能があります。つまりこのQuadro GP100を2,000台用意してスケールするようにうまく接続・活用できれば理論上は京コンピュータと同等の性能を持ったコンピュータが誕生します。
実はQuadro GP100が発表される以前のQuadro P6000などでは、この「倍精度」の演算能力が非常に冷遇されていました。それはNVIDIA社がゲーム用に非常に注力しており、設計コスト削減のために単精度を重視したStreamingMultiprocessor設計をQuadroでも使いまわしていたからです。
なんだかんだいってグラボの一番のお客さんはゲーマーです。CADをやったり科学技術計算をしている人なんて極々一握りです。だからこそNVIDIAは「単精度」演算能力を重視しておりそれはQuadro G100以前まではQuadroでも「単精度優遇」だったのですが、今回のQuadro GP100は今までのこの流れを一気にぶった切りました。
その理由は、IntelがXeon PhiでNVIDIAの市場を奪おうとしているため、NVIDIAが対Intelとして倍精度浮動小数点演算を重視したからです。
まとめると、このQuadro GP100はゲーマーからしても科学技術計算用途の人からしても十分な性能です。ただゲーマーからすると倍精度浮動小数点演算能力がオーバースペックなので1080Tiで十分でしょう。
・菱洋エレクトロ NVIDIA Quadro GP100 16GB


・HP NVIDIA Quadro GP100 1ZE81AT


・PNY NVIDIA Quadro GP100 VCQGP100-PB










6位: AMD Radeon VII【3.4585TFlops】
Boostクロック1,750MHz
Radeon Instinctと同じVegaアーキテクチャ採用で、製造プロセスTSMC7nmで同じです。
倍精度演算器の無効化比率は高く、単精度演算器の数の約1/4に留まっています。歩留まりを向上させるために動作しない倍精度ユニットを無効化しているようです。
有効化されているCU数はRadeon Instinct MI50と同じ60基です。
・ASUS RADEONVII-16G
![RADEONVII-16G [AMD Radeon VII 16GB HBM2]](https://m.media-amazon.com/images/I/41N5jhDBZXL._SL160_.jpg)







・Phantom Gaming X Radeon VII 16G








・PowerColor Radeon VII 16GB HBM2 AXVII 16GBHBM2-3DH








7位: NVIDIA Tesla K80【1.87TFlops】
このTeslaはアクセラレータであるためグラフィックス出力がついていません。HDMIやDisplayポートが一切ついていないわけです。その理由はこのボードは単にSIMD演算を行ったり各コアで並列計算をするための計算専用ボードだからです。
映像出力用としてはこのボードはほぼ利用価値がありませんが、深層学習などでCUDA Coreをコプロセッサとして用いて科学技術計算をしようとしている人にはとても価値があります。
ただ倍精度浮動小数点演算の能力が貧弱なので、金融分析などの倍精度・4倍制度以上を必要とする科学技術計算用途ではXeon Phiの方がいいでしょう。
・ELSA NVIDIA Tesla K80 ETSK80-24GER
RAM24GB。2015年1月発売。


8位: NVIDIA Quadro RTX 8000【0.5098TFlops】
Boostクロック1,770MHz、Streaming Multiprocessor72基、RAM48GB、TDP250W
Quadro RTXの中ではフラッグシップモデルですが、Turingアーキテクチャでは倍精度演算器がゼロなため、単精度の演算器で倍精度を擬似的に表現しています。そのためStreaming Multiprocessor1基あたりに存在する見做し倍精度演算器の数は2つです。よって次のようにFlops値が算出できます。
72基×倍精度演算器2×1,770MHz×2(FMA)=509,760MFlops
・ELSA NVIDIA Quadro RTX 8000 ENQR8000-48GER(VD6853)






・PNY NVIDIA Quadro RTX 8000 VCQRTX8000-PB




















9位: NVIDIA Quadro RTX 6000【0.5098TFlops】
Boostクロック1,770MHz、Streaming Multiprocessor72基、RAM24GB、TDP250W
Quadro RTX 8000とStreaming Multiprocessorの数もブーストクロックもTDPも同じです。
違いはベースクロックがRTX6000のほうが高く1,440MHz。あとRAMがRTX8000の半分の24GBというところです。当然ながら倍精度FLOPSは同じです。
・NVIDIA Quadro RTX 6000


・PNY NVIDIA Quadro RTX 6000 VCQRTX6000-PB










10位: NVIDIA Quadro P6000【0.375TFlops】
Quadro M6000の後継として2016年11月に発売されたグラフィックボードです。単精度浮動小数点演算能力は1080Tiの方が上ですが、倍精度浮動小数点演算能力ではこのQuadro P6000の方が上を行っています。深層学習なら1080TIの方がいいでしょうが、金融分析などの科学技術計算分野でコプロセッサとして使う人は1080TiよりQuadro P6000の方が高い演算能力を得られます。
・菱洋エレクトロ NVIDIA Quadro P6000 NVQP6000-24G


・ELSA NVIDIA Quadro P6000 EQP6000-24GER(VD6177)








・PNY NVIDIA Quadro P6000 VCQP6000-PB












・HP NVIDIA Quadro P6000 Q0V76A






・HP NVIDIA Quadro P6000 Z0B12AT

・HP NVIDIA Quadro P6000 Z0B12AA




11位: NVIDIA Quadro RTX 5000【0.3485TFLops】
Boostクロック1,815MHz、Streaming Multiprocessor48基、RAM16GB、TDP200W
Quadro RTX 8000/6000と比較してStreaming Multiprocessorは大きく減って48基です。歩留まり向上のためSMが一部無効化されています。
そのかわりBoostクロックは1,815MHzであり、Quadro RTX8000/6000より向上しています。
倍精度のFlops値は、SM48基×クロック1815MHz×SM1基あたりの見做し倍精度演算器2個×2(FMA)=348,480MFLopsとなります。
・NVIDIA Quadro RTX 5000








・ELSA NVIDIA Quadro RTX 5000 ENQR5000-16GER(VD6790)






12位: NVIDIA Tesla T4【0.2544TFlops】
Boostクロック1,590MHz、RAM16GB、TDP70W
Turing世代のアクセラレータの中ではフラッグシップモデル。しかし倍精度演算器を全く搭載していないため、単精度演算器で倍精度演算を模倣する形でFP64に対応しています。よって倍精度はものすごく低速です。
Streaming Multiprocessorは40基搭載。そしてTuring世代の倍精度浮動小数点演算能力は単精度の1/32であるため、SM1基あたりの見做し倍精度演算器の数はたった2個。
つまりSM40基×倍精度演算器2=80個の見做し倍精度演算器しかありません。
これを元に倍精度Flopsを計算すると、倍精度演算器80個×Boostクロック1590MHz×2(FMA)=254,400MFlops(0.2544TFLops)となり公称倍精度Flops値と一致します。
・Lenovo NVIDIA Tesla T4


13位: NVIDIA Quadro RTX 4000【0.222TFlops】
Boostクロック1,545MHz、Streaming Multiprocessor36基、TDP160W
Turing世代のQuadro RTX 5000の下位にあたるモデルです。Quadro RTX 5000より動作クロックが格段に低くなっています。Streaming Multiprocessorは、Quadro RTX 5000の48基から12基減って36基です。Turing世代のStreaming Multiprocessorは倍精度演算器を搭載していませんが、単精度演算器を使って倍精度の計算をするため見做し倍精度演算器はStreaming Multiprocessorあたり2個あります。
そうすると倍精度Flopsは、SM36基×Boostクロック1545MHz×倍精度演算器2個×2(FMA)=222,480MFlopsとなります。
・PNY NVIDIA Quadro RTX 4000 VCQRTX4000-SB












・PNY NVIDIA Quadro RTX 4000 VCQRTX4000-PB












・HP NVIDIA Quadro RTX 4000 5JV89AT


14位: NVIDIA Quadro M6000【0.19TFlops】
Quadro P6000より一つ古い製品です。単精度の能力も倍精度の能力もゲーム向けのGeForce GTX1080の方が高くなっています。発売時期に1年近い開きがあるので仕方ないとも言えます。
・ELSA NVIDIA Quadro M6000 24GB EQM6000-24GER 24GB
2016年4月発売。










・ELSA NVIDIA Quadro M6000 EQM6000-12GER 12GB
2016年4月発売。








15位: NVIDIA Tesla P4【0.17TFlops】
深層学習(ディープラーニング)に特化しているような構成のボードです。倍精度は不要とばかりにほぼ完全に削られています。単精度が重要な深層学習という応用分野でしか使えず、金融関連では厳しいです。
NVIDIAはIntelのXeon Phiと差別化するために深層学習分野に生き残りをかけているので、この分野に特化する方向性で今後も行くのでしょう。
またこの製品のメリットはTDPがたったの50Wしかないことです。Core i7 7700KがTDP91W、7700が65Wであることからその辺のホストプロセッサ用CPUよりも低消費電力です。
よってこのチップを搭載した製品はファンレスですし、冷却にさほど気をつかわなくてもケースファンさえ動いていれば余裕で冷やせるでしょう。
50Wと75W版はそれぞれ動作周波数からコア数からすべて同じです。なぜ消費電力が違って公称スペックが同じなのか謎ですが、演算器の数や周波数は同じだけれども、ソフトウェアがそれらをフルに同時に使い切れることなんてほぼないのだから、高々50Wに抑えるように内部的にパイプラインを制御したり命令発行を制御するようになっているのかもしれません。家庭用の趣味として使うなら75Wでいいでしょうが、最初に上限の電源容量ありきで研究室の一角にコンピュータを導入しなければならないときには50Wモデルにしつつ台数を増やすことが優先されるでしょう。
・ELSA NVIDIA Tesla P4 50W ETSP4W-8GER
RAM8GB。TDP50W版。動作周波数、メモリ容量、演算器数などのスペックは75W版とすべて一緒。
・ELSA NVIDIA Tesla P4 75W ETSP4-8GER
RAM8GB。TDP75W版。
16位: NVIDIA Quadro M2000【0.0566TFlops】
・ELSA NVIDIA Quadro M2000 EQM2000-4GER
Displayport出力×4。2016年4月発売






Turing世代アーキテクチャにおける倍精度浮動小数点演算
Turing世代はVolta世代からどのように倍精度浮動小数点演算の扱いが変わったのか解説していきます。
Turing世代では倍精度演算器ゼロ
Volta世代のQuadro GV100では、単精度の演算器数の1/2が倍精度の演算器数でした。つまり倍精度は全く冷遇されていなかったわけです。
しかしTuring世代では倍精度の演算器がごっそり削られてゼロ個になりました。下図がTuring世代のStreaming Multiprocessor1基の内部です。
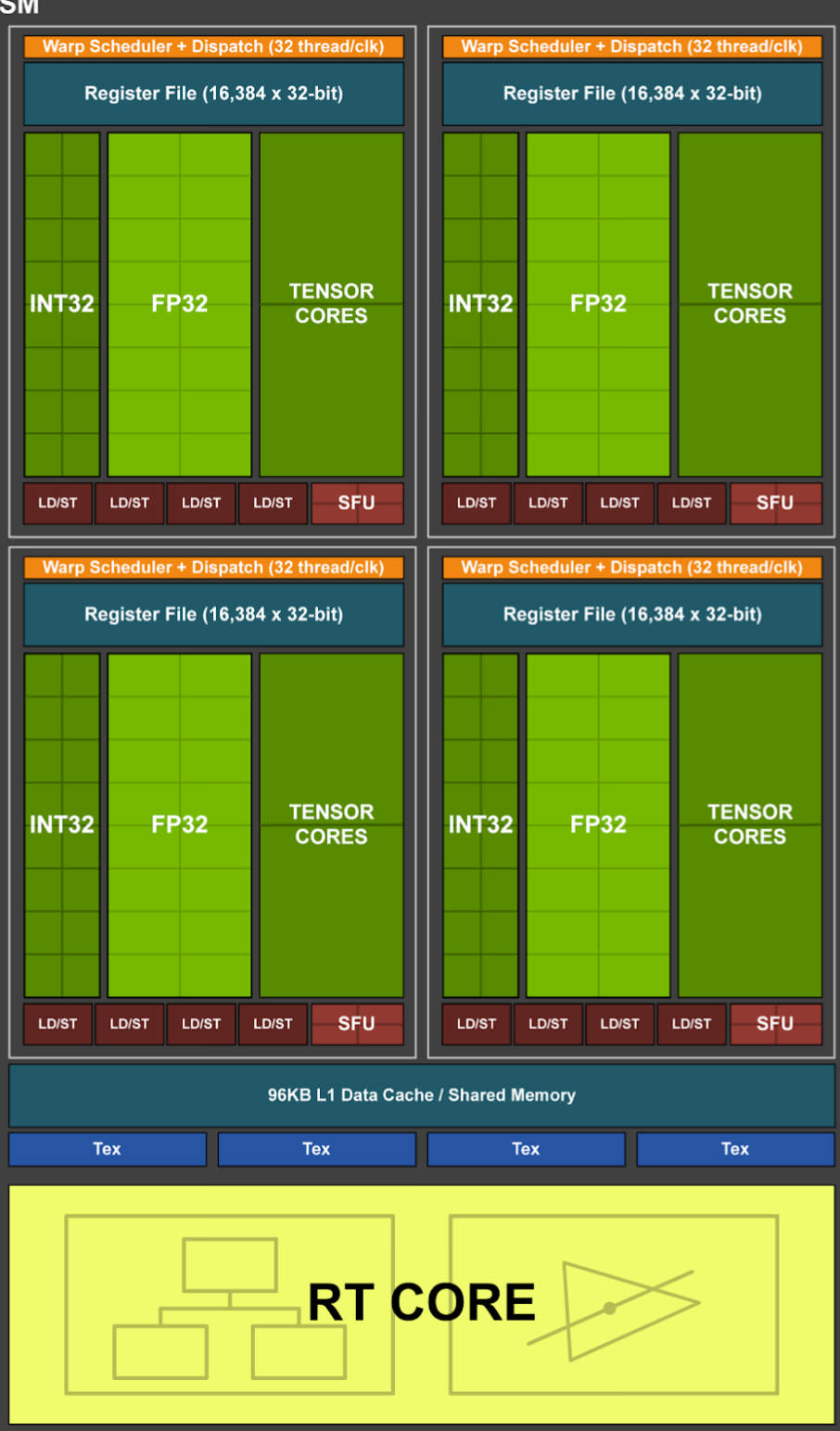
4ブロックある点はVolta世代と同じで、しかも32bit整数と32bit単精度の演算器の数も一緒です。さらにTensor Coreの数もVolta世代と同じです。では何が違うかと言うと、SMに1つのRayTracing Coreを搭載したことが異なります。
このRay Tracing Coreを搭載するために、64bit倍精度浮動小数点演算器がまるごと削られました。チップ上の面積を捻出するためです。
Turing世代では単精度の演算器で倍精度演算を模倣している
ではTuring世代では倍精度の浮動小数点数を扱えないのかと言うとそうではありません。倍精度の小数を2つの単精度の小数として表現し、それに対して乗算・和算を行えば倍精度浮動小数点数演算を「模倣」できるからです。つまりエミュレーションのような形で、Turing世代では倍精度浮動小数点演算を実行しています。当然ながらものすごく遅いです。
CUDA Coreは倍精度(FP64)演算器を含まない
ゲーム用のグラボの場合はCUDA Coreの数で性能を比較されます。
そもそもCUDA Coreとは何なのか、その範囲を明確にしておきます。
NVIDIA GPUの場合はStreaming Multiprocessor(SM)の集合体が1つのチップを構成しています。例えばGV100なら80基のSMが存在し、ゲーム用グラボのRTX 2080Tiなら68基のSMが存在します。以下の図がSM1基分の内部を示しています。
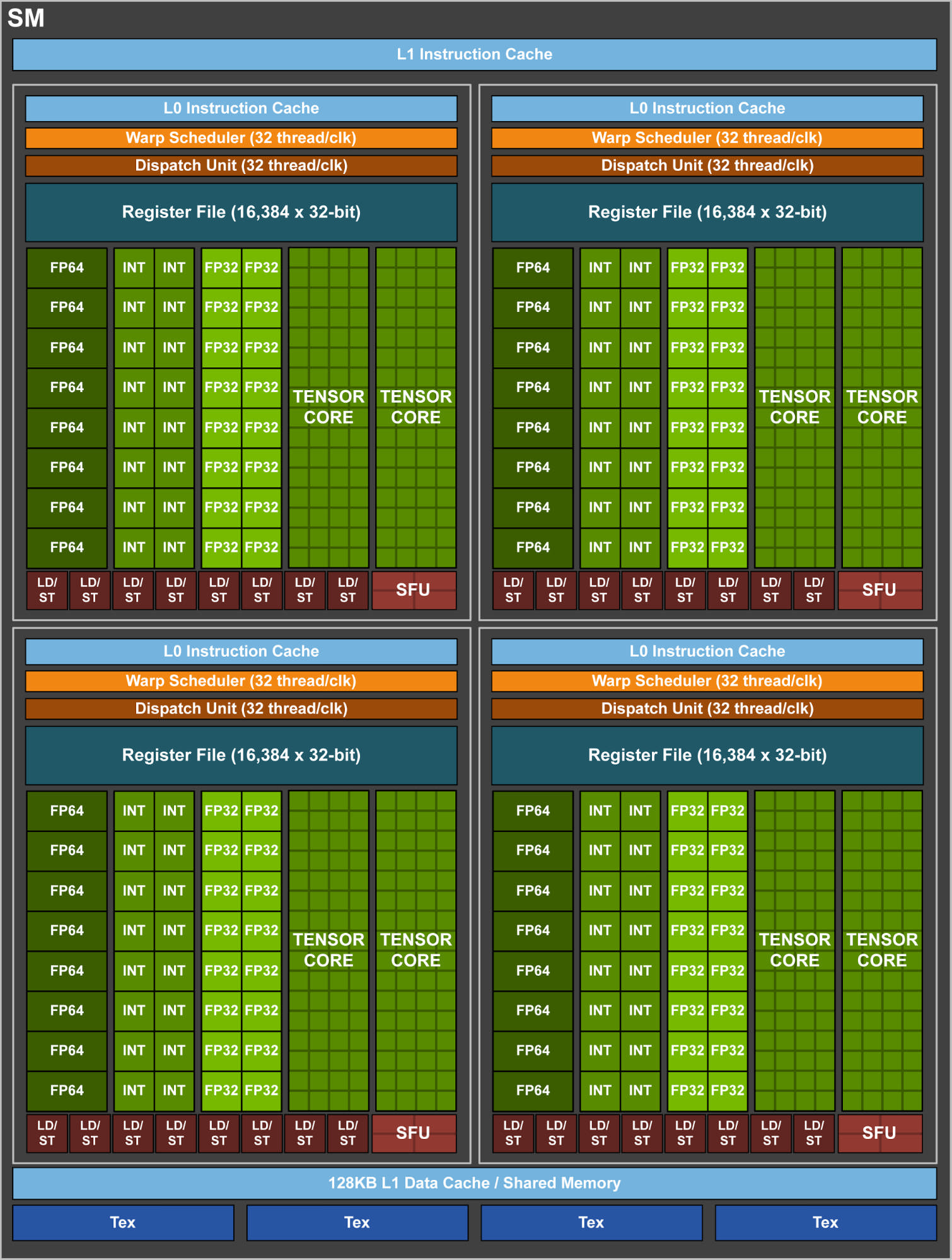
SM1基あたり大きく4つのブロックが存在することがわかります。下図はSMの中にある4ブロックのうちの1ブロックを表したものです。
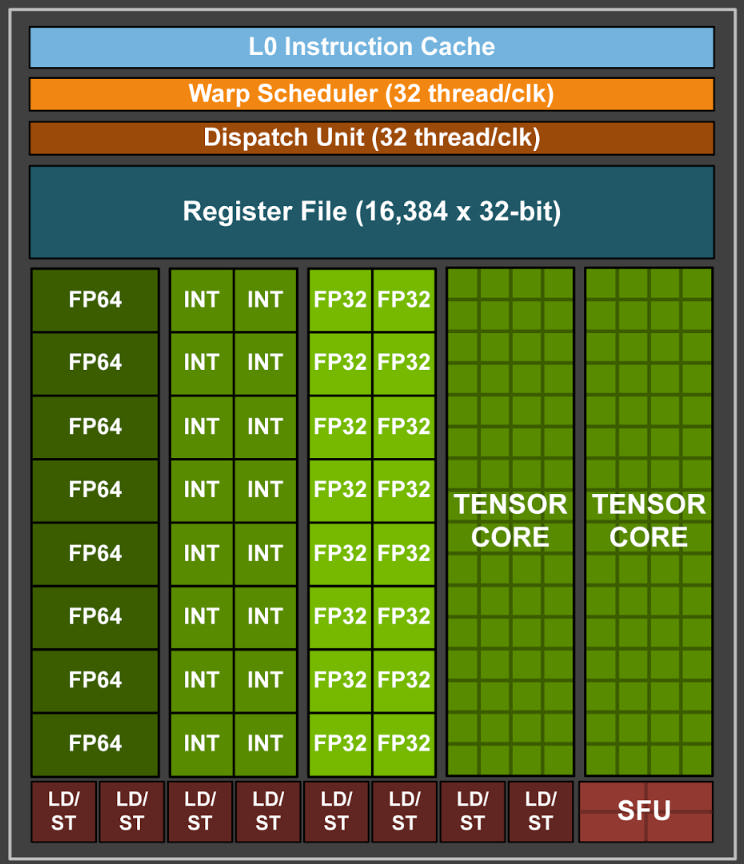
この図の中央に「INT」と書かれたブロックが16個あります。これは32bit整数の演算器です。そしてその右側には「FP32」と書かれたブロックが16個あります。これが単精度浮動小数点数演算を実行する演算器です。この「INT」と「FP32」を1つずつワンセットにして1CUDA Coreになります。CUDA Coreとは32bit整数の演算器と単精度32bit浮動小数点数演算器の集合です。つまりこの1ブロックの中には16のCUDA Coreが存在します。
そして先程、1基のSMには4ブロック存在することを説明しました。つまりSM1基で64のCUDA Coreが存在します。さらにQuadro GV100には80基のSMが存在するため、合計80×64=5,120のCUDA CoreがGV100には存在します。これがシェーディングユニットと呼ばれている部分です。
しかしこのCUDA Coreの中には倍精度の演算器は含まれていません。32bit単精度のものだけです。
上図の一番左にはFP64というブロックが8個あります。これば64bit倍精度浮動小数点数演算用の演算器です。つまり倍精度用の浮動小数点演算器は「CUDA Coreの外側」にあります。
Quadro GV100の場合、この64bit倍精度浮動小数点演算器の数は、SM1基あたり8個存在するため、80基×4ブロック×8コア=2,560個存在します。
CUDA Coreの5,120個の半分であることがわかると思います。そのためFLOPS値でみても単精度16TFlops、倍精度8TFlopsとなっています。
倍精度に関しては最新の世代ほど高性能とは限らない
以上のように、Turing世代では倍精度浮動小数点演算器がごっそり削られゼロになりました。Ray Tracingコアを搭載するためです。NVIDIAがRay Tracing重視を続ける限りは次世代でも倍精度の演算能力はあまり期待できません。