![]()
私も当初はRyzen発売を好意的に受けとめていましたが、実際の用途からかけ離れたベンチマークを回すこと自体が目的の人以外にはメリットの無いCPUです。
多くの人はパソコンをベンチマークを回すために買うのではなく、ウェブサイト検索・ゲーム・新卒の就職活動・大学のレポートや卒論修論作成・YoutubeやTwitch視聴・Word/Excel/PowerPoint作成・プログラミング等をするためにパソコンを購入します。
職場や大学でのパソコン使用を含めて、そういった「実際的な用途」ではIntel Coreが圧倒的に優秀であり、動作が不安定で1コアあたりの性能が低いAMD Ryzenをあえて選ぶのはよほどの物好きだけです。
コア数の多さでもIntel Coreに追い抜かれてしまったAMD Ryzen唯一のメリットは「同じコア数同士で比較するとIntel CoreよりAMD Ryzenの方が安い」といった価格面だけです。しかし安い分だけソフトウェアの動作が不安定といった「安物買いの銭失い」になるデメリットもあり、AMD Ryzenの不安定なところが法人等の業務用でAMD Ryzenが使われずIntel Coreが好まれる理由です。YoutubeやTwitchの動画配信者のようにパソコンを使って高収入を得ている人ほどパソコン絡みのトラブルで収益機会を失わないようにIntel Coreを使用している傾向にあります。
Intel CoreとAMD Ryzenの構図をわかりやすく例えると「歴史が長く信頼性が高いNTTドコモ(≒Intel)の牙城に対して楽天モバイル(≒AMD)が価格の安さで挑んでいるけど不安定で実用性に乏しくしかも速くないため楽天(≒AMD)が負け続けている」ことと似ています。
2017年に発売された第1世代Ryzen(Summit Ridge)プロセッサについてはこちらで評価しています。
2018年に発売された第2世代Ryzen(Pinnacle Ridge)プロセッサについてはこちらで評価しています。
2019年に発売された第3世代Ryzen(Matisse)プロセッサについてはこちらで評価しています。
また、第4世代Ryzen5000シリーズプロセッサについては本記事でもベンチマーク評価していきます。
私は今後バックアップ用の副系パソコンを自作する予定で、既にケース・ファンレス電源とRyzenにもIntelにも対応したCPUクーラーも購入して残りはマザボCPUメモリを買うだけなのですが、Ryzenが良かったらそれを選択するでしょうが残念ながら今の情勢だとIntel Coreを購入することになりそうです。
AMD Ryzenは2017年に発売された第1世代から貫徹しているコンセプトがあります。それはコア数の多さです。「シングルスレッド性能ではIntel Coreに勝てないけどマルチスレッド性能だけはIntelに対し絶対に勝つ」がRyzenの存在意義でした。
しかし2022年になり「シングルスレッド性能だけでなくコア数もマルチスレッド性能もIntel Coreが上」という状況が到来し、AMD Ryzenの存在意義が問われる危機に直面しています。
まず本稿の構成としては、最初に「RyzenとIntel Coreの評価手法」を説明します。続いて「AMD Ryzenが登場した際のCPU業界の背景」を記載し、次に「ベンチマーク評価」に移ります。その結果を受けた「Conclusion(結び、結論)」をまとめ、そして「AMD Ryzenの今後の展望」を記載し、最後に「参考文献」を掲載しています。
Intel vs. AMDの今後:無いと困るIntelと、無くても困らないAMD
2024年3月に面白い事象が発生しました。米国政府が「CHIPS法」を根拠に用意した530億ドルのうち85億ドル(1.3兆円)をIntelに配分することを決定しました。Intelのファウンドリ用だけでもこの金額です。これらはTSMCやSamsungといった「今後戦争で壊滅すると思われる地域」依存から脱却し、米国内に工場を作るための補助金です。
一方で同じ2024年3月にAMDにとっても芳しいニュースがありました。AMDが製造する機械学習向けプロセッサの中国への輸出に対して米国政府がストップをかけたというものです。
米国政府はIntelを贔屓する一方で、徹底的にAMDいじめをしているのが面白いところです。
それもそのはず、Intelは無いと困る国策企業だから米政府は巨額の国内回帰補助金出していますが、別にAMDは無くても困らない不要企業だからです。IntelとQualcommとNVIDIAさえあれば米国のプロセッサ(汎用プロセッサor特定目的プロセッサ)は賄えてしまいます。
AMDが無くなっても困ることはありません。AMDは独自ファウンドリを持っておらず、しかもCPUやGPUにいたってはIntelとNVIDIAといった優秀な先行企業が存在するため、AMDが米国政府から大切にされていないのも頷けます。
もし台湾や半島で有事があればNVIDIAやQualcommはファウンドリをTSMCからIntelのファウンドリに切り替えるだけで済みます。AMDはTSMCが使えなくなったらIntelに頭を下げて委託生産してもらうのでしょうか。非常に見どころです。
AMD愛好家の精神的支柱Ryzen 7000シリーズが投入されても負けが約束されてしまっている悲しさ→実際に敗北
2022年10月以降、AMD愛好家は”臥薪嘗胆”真っ只中です。第12世代Alder Lakeに対し2022年4月に発売されるRyzen 50003Dシリーズで対抗したかったものの、3Dキャッシュのせいでクロック上昇に関し物理的に制約がかかりオーバークロック不可となってしまう悲報が舞い込んできたため、既にAMD愛好家の期待の矛先は2022年9月発売のRyzen 7000シリーズに向いていました。しかし実際に発売されてみると1コアあたりの性能は微妙で、シングルスレッド性能は2021年発売の第12世代Intel Core(Alder Lake)にも負けてしまう有様でした。
面白かったのは2022年9月のRyzen7000シリーズ発売直後でもAMD愛好家はすぐには購入しようとせず様子見をしていたことです。なぜなら一ヶ月後の2022年10月発売の第13世代Intel Core(Raptor Lake)に負けてしまうと、「Intelに対し負けてしまう欠陥CPUをAMD愛好家のなけなしの財産をつぎ込んで掴んでしまう」ことになるからです。
その悪い予感は的中し、Ryzen7000シリーズはシングルスレッド性能だけでなくマルチスレッド性能でも第13世代Intel Coreに対し負ける局面が多く、AMD愛好家をしても「今回のRyzenはうまくない」と言わせしめてしまうほどでした。
そのせいか2022年10月の第13世代Intel Core発売以降、急激に型落ち品のRyzen5000シリーズが売れ始め、Ryzen7000シリーズはkakaku.comの売れ筋でIntelより下位に落ちぶれました。なぜならRyzen5000にしておけば「第13世代Intel Coreと比較されずに済む」からです。Ryzen7000を買ってしまうと第13世代Intel Coreとタイマンを張らなければならないため敗北の屈辱を味わいます。しかしRyzen5000なら第13世代Intel Coreと比較されようがないため、ある意味敵前逃亡としてRyzen5000が急浮上しました。しかしRyzen5000を動作させるには古い世代のAM4マザーボードが必要です。既にAM4マザーボードは生産打ち切りになっており、中古市場ではAM4マザーボードが高騰し、AM5マザーボードより価格が高くなってしまう逆転現象が起きました。新しく安いAM5マザーボードを買わず古く高いAM4マザーボードを高掴みするという愚行を犯してまでしても、Intelに対し負けが約束されているAM5マザーボード+Ryzen7000を買いたくなかったということになります。
既にAM4マザーボードを所有しているのなら、Ryzen5000を買ったほうがRyzen7000よりも安上がりになるので理屈はわかります。Ryzen7000の場合AM5マザーボードを購入することも必須だからです。しかしAM4マザーボードが中古市場で高騰してるということは、AM4マザーボードを持っていない層までもRyzen5000をあえて選んでいることを意味し、それは第13世代Intel Coreと比較され負けの屈辱を味わいたくないという敵前逃亡の動機があるからです。
そしてAMDはこれまでマイクロアーキテクチャの劣りを挽回するためにTSMCの微細化技術が頼みの綱でしたが、2025年までTSMC4nmを使い続けなければならない羽目に陥りました。これによりAMD Ryzenは2024年発売のRyzen 8000でもTSMC4nmを用いるお寒い結果となってしまい、同じ年度に発売される第15世代Intel Core(Arrow Lake)に対しRyzen 8000(Zen5)が敗北することが既に確定しています。
【サーバ向けCPU:2024】
Granite Rapids(Intel 3) vs. EPYC Turin Zen5 (TSMC 4nm):
TSMC 3nmを使う予定が結局TSMC 4nmに後退 この時点で既にIntelには勝てずAMDの敗北が確定
AMDは2025年までTSMC4nmで我慢を決断
次にサーバ用CPUです。モバイル向けMeteor Lakeで採用されたRedwood Coveマイクロアーキテクチャはサーバ用のGranite Rapidsでも採用されます。ただしサーバ用ではプロセスを一歩進めてIntel 3となります。AMDはこのGranite Rapidsに対し、Zen5マイクロアーキテクチャを採用したTurinというコードネームのEPYCで対抗することになります。
Zen5世代になればさすがのAMDでもTSMC 3nmを使いたくなります。IntelはAMDより先にTSMC 3nmを使わせて貰っているからです。
しかし、TSMC 3nmもSamsung 3nmも歩留りが向上せず製造プロセス実現に苦戦しておりコストが高騰しました。
AMDは本来Zen5世代ではTSMC 3nmを使うことしか眼中にありませんでしたが、TSMC 3nmのコストが高すぎるためTSMC3nmでは費用対効果が割に合わないと判断。AMDはSamsung 3nmに切り替えることも検討していました。しかしSamsungは4nmプロセスでも結果は芳しくなく、Samsung 4nmはトランジスタのスイッチング性能が伸びずに事実上の失敗の烙印を押されています。Samsungの製造プロセスを使ったNVIDIA Ampere世代のGPUはアーキテクチャこそ優秀なのに、高消費電力の割にいまいち性能が冴えなかったのもSamsungのプロセスを使ったせいです。Samsungは3nmも苦戦しており、TSMC 3nmの代替にはなりそうもありません。
Intelは自社ファウンドリを持ってることもありTSMC 3nmの使用は部分的ですが、AMDは汎用コアも含めて全てをTSMCで生産するわけですから歩留まりの悪化はコスト高と供給量減少に直結します。そこでAMDはZen5マイクロアーキテクチャで製造プロセスを妥協しTSMC 4nmにするという話が出ています。TSMC 3nmを使えれば、Intel 3と互角でなんとか勝負になるかもしれません。しかしAMD Zen5ではTSMC 4nmになることが濃厚です。
実はTSMCは3nmを既に提供できています。問題はそのコストが高すぎることです。現在米国のビッグテック企業群はAI(生成AI含む)のバブルが弾けつつあることと中国の景気が急速に悪化していることから、汎用プロセッサ需要が著しく後退しています。そんな中でTSMC3nmを採用してAMDプロセッサを作ったところでコストを回収できなくなってしまいました。そこで安いTSMC4nmを2025年まで使うことをAMDが決めてしまいました。
2021年時点では「Zen5ではTSMC 3nmを使える」と報道されていたため、これならIntel 3プロセス相手になんとか勝負になるとAMD愛好家は安堵していました。しかし2022年になってから「Zen5では歩留まりの悪いTSMC 3nmを諦めTSMC 4nmになるかもしれない」と悪い知らせが入りAMD愛好家が意気消沈しているという状況です。
【デスクトップ&モバイル向けCPU:2024】
第15世代Arrow Lake(Intel 20A,TSMC 3nm) vs. Ryzen 8000 Zen5(TSMC 4nm)
第15世代Intel Core(Arrow Lake)のデスクトップ版ではTSMC 3nmのみならずさらに微細化を進めたIntel 20Aプロセスが採用されます。これに対抗するならAMDはTSMC 3nmプロセス程度を使ってチップを製造しなければなりませんが、実際はRyzen 8000シリーズ(Zen5)で採用されるのはTSMC 4nmになってしまう蓋然性が高くなっています。
米国のビッグテックの成長力が削がれてきたことと中国の消費が極めて弱い不況によってプロセッサ(MPU)需要が急速に後退しており、TSMC3nmを使うと採算割れすることを恐れたAMDは日和って2025年まで4nmを採用することを決めてしまいました。一方でIntelは第15世代Arrow LakeでTSMC3nmを使います。
ここまで来るともはやAMDが一方的に「Intelに対抗している」と自称しているだけで、IntelからするとAMD Ryzenはカウンタパートとしても見てもらえないでしょう。
Intel 4とIntel 3の後, Intel 20A, Intel 18Aが控えており、AMDがキャッチアップできる余地全く無し 再びAMDは長く暗いトンネルへ
Intel 4とIntel 3は2023年において既に生産が現実のものになっています。Meteor Lakeの汎用コアにおいてはIntel 4が採用され、iGPUにおいてはIntel 3が採用され2023年度に発売のノートパソコンに搭載されました。
その後、2024年に発売されるデスクトップ向けプロセッサ第15世代Intel Core(Arrow Lake)ではIntel 20Aが採用されます。同時にIntelは第15世代Intel CoreにおいてTSMC 3nmも使います。
AMDが可哀想なのは、これまで長くTSMCのプロセスを使ってきたのにも関わらず、TSMCから割り当てて貰えたのがAppleが使い終わったお下がり製造プロセスだったということです。その一方で、長らく自社製造プロセスにこだわってたIntelが急に割り込んできて最新のTSMC 3nmの契約をAMDより先に取ってしまいます。
実はAMDはIntelの1/10程度の規模しかない弱小企業です。当然Appleよりも格段に小さい企業です。TSMCは実績のある大手企業のIntelとAppleを選んだことになります。
概要:「マルチスレッド性能の優位性」を潰され岐路に立たされているAMD Ryzen
2017年に第1世代Ryzenが発売されて以来、AMD Ryzenでは同種の汎用コアの数をひたすら増やす手法によって「マルチスレッド性能だけはIntelに勝つ」ことを存在意義として発展してきました。
しかしIntelは2021年から「シングルスレッド処理性能の高さは高性能コアに任せ、マルチスレッド処理性能の高さは低消費電力なAtomコアをひたすら増やして確保」という手法を採用し、マルチスレッド性能でもAMD Ryzenを超えてしまう場面が増えてきました。実際の用途では全く登場しないような処理を実行する机上の空論ベンチマークとしてCinebench R23(Multi)がありますが、このCinebenchはコア数が多いRyzenで高いスコアが出るためにAMDユーザにとってはお気に入りのベンチマークです。しかし、第12世代Intel Core発売以降、このCinebench R23(Multi)でもIntelに逆転される事態が発生するようになってきました。
そして2022年に発売される第13世代Intel Core(Raptor Lake)とZen4世代のRyzen7000シリーズ(Raphael)との比較では、完全にIntel Coreの勝利となりました。Ryzen愛好家をしても「今回のRyzen(Zen4)はうまくない」と言わせしめるほどの失敗作がRyzen7000シリーズです。
AMD Ryzenのように同種の汎用コアをひたすら増やす手法だとどうしても1コアあたりの性能が低くなります。他のコアに電力枠を奪われてしまうためです。そうなると今後のRyzenが採る方策は以下の3つしかありません。
1.のままだといずれマルチスレッド性能の高さでIntelに追い抜かれてしまうのは確実です。Intelの低消費電力コア(Atomマイクロアーキテクチャ)の方がコア数を増やしやすい(スケーラブルに増加させやすい)ためです。
もしくは3.のように1コアあたりの性能に特化する真逆のコンセプトに転換する選択肢もあります。しかしこれはIntelより優秀なマイクロアーキテクチャを設計しなければならずAMDには無理筋な選択です。そもそもAMDが2017年の第1世代Ryzenから「コア数をひたすら増やす」手法に傾倒したのは、1コアあたりの性能の高さではIntelに絶対に勝てないから、AMDが生き残るためには隙間産業としてコア数を増やす方向を選択せざるを得なかったという背景があるためです。
そうなるとAMDもIntelのハイブリッド手法をパクって消費電力を低くした異種コアを設定し、消費電力を低くしたコアを増やしていくしかありません。「マルチスレッド性能向上でどん詰まりになったAMDがハイブリッド手法を採用しIntelの軍門に下った」と揶揄される一時的な恥を忍んででも結局は2.の手法を採用せざるを得ないでしょう。
そもそもIntelが採用したハイブリッド手法は、学術上はヘテロジニアス・マルチコアプロセッサ手法に分類される非常に古典的な方法であり、情報工学分野で使う大学学部レベルの教科書にも当たり前のように載っているレベルです。モバイル機器で長らく使われてきた汎用コア+マルチメディア処理特化コアも異種コアに分類されるため、決して真新しい手法ではありません。
にもかかわらずIntelのハイブリッド構成が注目されたのは、汎用コアのみでヘテロジニアス・マルチコア(異種コア)を実現したためです。普通は異種コア構成にする場合「汎用(general purpose)コア+特定目的(special purpose)コア」といった構成を採ります。しかしIntelのハイブリッド構成は、「汎用コア(高性能)+汎用コア(低消費電力)」であり、低消費電力コアも汎用コアであるところがこれまでの異種コア手法とは違う新規性になっています。
動画エンコードや将棋の局面探索など、1コアあたりの性能よりも並列処理性能だけを目的とするならRyzenも可 しかし現在ではIntel Coreが並列処理性能でもAMD Ryzenを上回ってしまう
Ryzenが叩かれている部分は何かというと、1コアあたり、または1スレッドあたりの性能の低さです。これはコア数を増やすと消費電力が増大してしまうため、動作周波数を下げなければTDPが高止まりしてしまう技術上の問題で仕方のないことではあります。
しかし1コアあたりの性能が低くなることは、ウェブサイトの閲覧、Word・Excelなどのテキスト作業、会計ソフトの入力のような事務作業用途で圧倒的に不利になります。
Excelは既に入力した数式の再計算処理は自動的に並列化して実行してくれますが、入力操作やグラフの作成時など計算処理以外のシート操作部分ではマルチコアの恩恵を受けることができません。1コアあたりの性能が高いほうが有利です。
またWordはExcelよりもさらにコア数増加のメリットを受けることができず、Word用途においてコア数が多いことはほぼ何もメリットがありません。Wordなら尚更1コアあたりの性能が高いほうが編集時にもたつく時間の短縮に繋がります。
さらに、プログラミング作業用途を考えている場合でもRyzenのような多コアは不利であり、VisualStudioでの作業やビルドやデバッグはIntel Coreのほうが高速です。並列処理プログラムを作ったあとにそのプログラム自体を実行する段階ならRyzenでも”あり”です。しかしプログラム作成段階では1コアあたりの性能が低いと非常に作業効率が悪くなります。最初から並列化してマルチコア・プログラミングすることはまずなく、まずはシングルスレッドのプログラムを作ってバグを潰してから並列化するという手順を踏むので、趣味でVisualStudioを使って深層学習や金融分析をしているような用途で使う人はIntel Coreの方が作業効率が圧倒的に高いです。
さらにIntelにはMath Kernel Libraryという非常に数値計算精度が高いライブラリを利用できます。数値計算乗の小数誤差を小さくできるのみならず自動的にSIMDを活用し高速化してくれるライブラリです。このMath Kernel Libraryを利用する際の恩恵を受けられるのがIntelプロセッサの非常に大きなメリットです。
SIMD演算命令を活用できる1コアあたりの性能の高さが重要な数値計算・数値解析・科学技術計算といった分野の作業をするのなら、残念ですがRyzenが選択肢として載ることはまずありません。大学や大学院などでアカデミックな分野で使いたい人もIntelにしておいたほうが無難です。つまりRyzenは遊び向けということです。
ゲーム用途に関しては2017年に爆発的に大流行したPUBGは当時から「Ryzenに対応していないから遅い」と言われていましたが、Ryzenに対応していないというのは「PUBGの実装ではスレッドが並列化されていない」ことを意味します。実はPUBGのようなバトロワゲー以外ならRyzenの性能はそこまで悪くはありません。しかしTwitchで常に視聴者数上位のShakaやStylishnoobといった大御所配信者は少なくとも2016年当時からIntel Coreを使い続けており、ゲームが単なる遊びではなく重要な収入源になっている人達はIntel Coreを使っています。なぜならRyzenの不安定さやPCパーツの相性問題によってゲームや動画配信ができない事態に陥ると機会損失が大きいからです。
このようなRyzenの完成度の低さから来る不安定さ(信用の無さ)が、AMD Ryzenが未だに大企業や官公庁といった法人で殆ど採用されない最大の要因でもあります。
1コアあたりの性能が低くても問題ない用途があるとしたら将棋ソフトくらいですが、そもそもパソコンで将棋をやる用途を想定してPCを買う人なんて全体からみたら微々たる比率に過ぎません。
将棋については人工知能(機械学習)を応用し研究してきた第一人者で、私も基調講演を聴いたことがある松原仁教授が専門なので彼の論文を読むのが最適ですが、簡単に言えば各局面をノードとし、打つ手によって局面をツリー状に分枝(分岐ではなく分枝)させ、「この局面は勝つ見込みがない」と評価関数で判断したら分枝を止める(それ以上その局面を探索するのを止める)のがコンピュータ上の将棋です。ある局面からAという手とBという手で分かれる局面はそれぞれ完全に独立しています。つまりそれぞれの局面から伸びる枝は別々のコアで実行できます。将棋のシミュレーション(局面探索)は非常にスレッドレベル並列性が高く、これが将棋はマルチコア用途として向くと言われる所以です。
逆に言えば、そのような特殊な用途でしか多数のコアを使い切れる用途はありません。日頃からパソコンで将棋をする用途なんて非常にレアであり、そんな用途よりもWord/Excelの作業が快適だとか、グラフィックの描画で高いフレームレートを出せる、といったようにシングルスレッドに大きな負荷がかかるアプリケーションの応答速度が高速化されて、「待たされずに済む」方が多くの人にとってメリットがあります。
現在では、Intel Coreは1コアあたりの性能の高さでもRyzenに勝った上で、Intel Coreのコア数をRyzenよりも増やすことにも成功し、「コア数だけは多いRyzen」といったAMD Ryzenの優位性をIntelが潰してしまいました。「1コアあたりの性能も高いしスレッドレベル並列処理性能も高いIntel Core」と「1コアあたりの性能が低いけど価格は安いAMD Ryzen」といった価格面での棲み分けになってきています。
1コアあたりの性能が低くてもAMDがコア数を増やす背景
チップあたりのコア数を増やすマルチコア化が活発化したのは2000年代半ばです。しかしそれ以前でもマルチプロセッサでコア数を増やす手法がありました。コア数を増やしてコンピュータを高速化する手法はMIMD(Multiple Instruction Multiple Data)に分類されます。このMIMDという概念が提唱されたのは1966年と記載されています。こんな大昔から「今流行りのコア数を増やす手法」の原点が提唱されており、コンピュータ・アーキテクチャの教科書の前半部分で必ず載っているお決まりの分類であるほど古典的な手法です。
こんな大昔に提唱された概念がなぜ今流行しているかというと「クロック周波数を引き上げるために電圧を上げると半導体の微細化が進んだことでリーク電流が大幅に増加してしまいこれ以上動作クロックを上昇させるのが難しい」ことで「コア数を増やさざるを得なくなっている」からです。「古典的な(classical)」というのは古いという意味ではなく「昔も現在も普遍的に通用する」という意味なので、そういった意味でMIMDは古典的です。
現在のCPUのクロックはベース4GHz~最大5GHz程度です。2000年代前半に登場したPentium4でも動作クロック4GHz程度です。それから20年近く経過しているのにもかかわらず、未だに4GHz~5GHzをうろうろしているあたり、動作クロックは年数の経過とともに全く向上していないことがわかります。
できれば動作クロックが6GHz,7GHzと伸びていってシングルコアの性能が年率50%以上で向上し続けるのが理想ですが、動作クロックを引き上げるためには電圧を引き上げることも必要で、電圧を上昇させると半導体の微細化が原因で消費電力が急増してしまいこれ以上動作クロックを引き上げるのが難しくなりました。
実は2003年まではシングルコアの性能向上が年率平均+52%を記録していました[Hennessy&Patterson, 2017]。これはアーキテクチャの改良による要因が半分、もう半分は半導体の微細化によるクロック周波数向上です。つまりアーキテクチャの改良と半導体の微細化によるクロック周波数向上の両輪によって年平均+52%の性能向上が実現されていました。
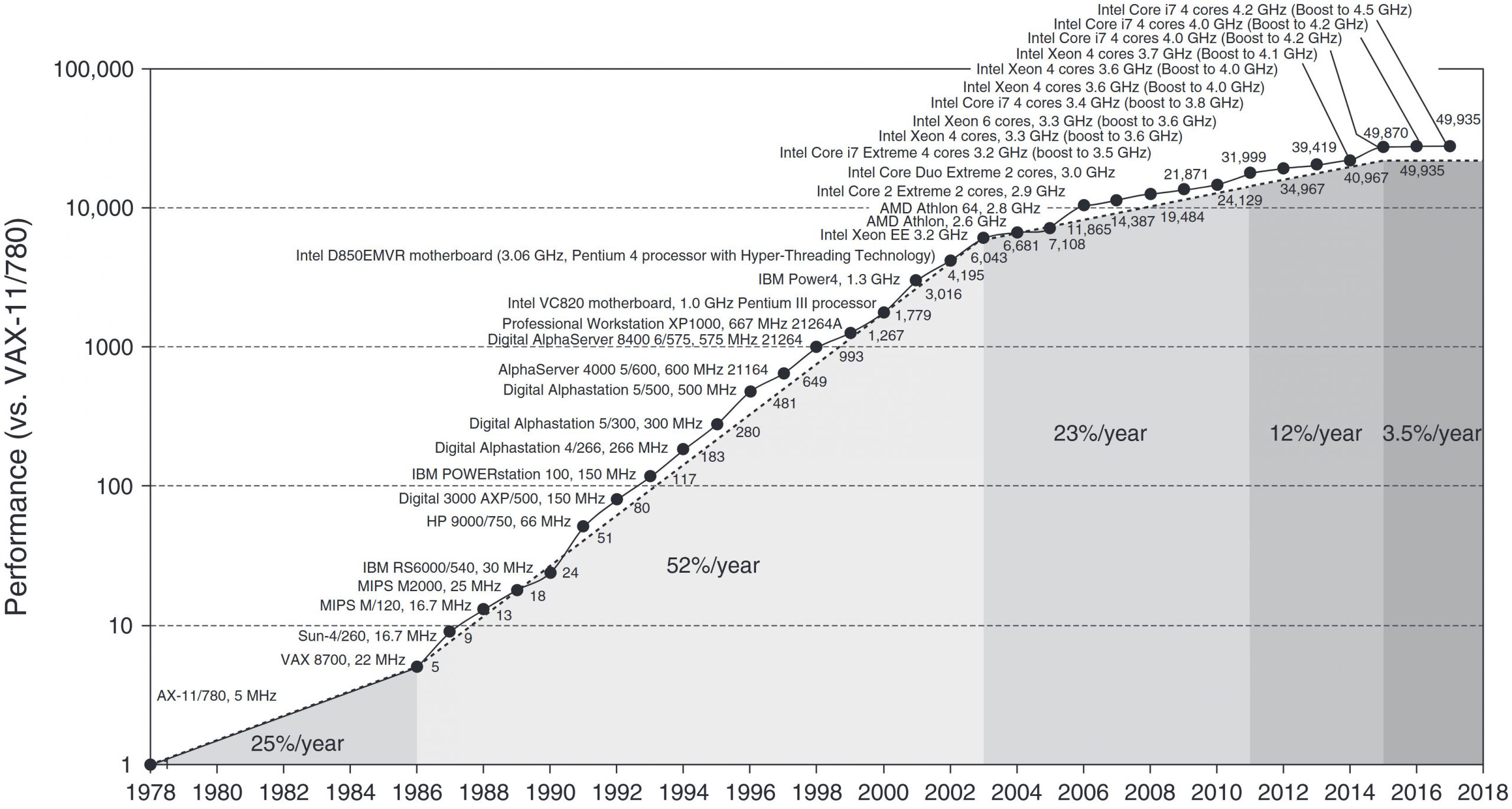
[Hennessy&Patterson, 2017]
しかし2003年頃から微細化が逆に仇となりリーク電流が大幅に増加しクロックの上昇が鈍りました。これは丁度Pentium4の時期とかぶります。
2004年以前までは「Dennardスケール(デナード比例縮小則)」が効いており、「トランジスタを微細化することでトランジスタが高速化するだけでなく消費電力も下がる」という非常に理想的な状況が続いていました[Hennessy&Patterson, 2017]。これは「微細化でトランジスタ数が2倍になってもチップ面積が一定なら消費電力も一定」を意味します。
しかし、この追い風は2004年で終焉します。この頃からプロセッサの性能向上は平均で年率23%程度になります。原因は微細化に伴いリーク電流が増大し、クロック周波数を引き上げるために必要な消費電力(≒単位時間あたりの発熱量)を引き上げることが難しくなったことが一つ。さらに命令レベル並列性を抽出し切ってしまい命令レベル並列処理の性能向上の恩恵を受けづらくなったためです。
そして2011年以降は4コア以上のマルチコア化が普及し、現在のAMD Ryzenのような「コア数のカタログスペックによる見せかけだけの性能競争」の先駆けとなる時期に入りました。しかし、アプリケーション・ソフトウェア内部のスレッドレベル並列性は非常に限られており、コアをいくら増やしてもそれ以上性能が伸びない限界があります。これは理論的に「アムダール(Amdahl)の法則」で知られており、情報処理技術者試験の午前問題で出題されてるくらい初歩的な基礎知識です。アプリケーション内部で50%部分が並列化可能で、残り50%が並列化不可能(逐次実行のみ)だとすると、コア数を100コアと増やしたところで性能向上は高々2倍です。100倍にはなりません。
それどころか、現実のアプリケーションでは10%が並列化可能で、残り90%は逐次実行しかできない(並列化できない)特性を持っています。そうなるとその10%の部分を100コアも使って並列化したところで、シングルコア比でたった+11%しか性能向上しないことになります。
以上のように、半導体の微細化が進むに連れてリーク電流の増大し、その結果クロック性能向上がほぼゼロになり、アーキテクチャの改良による要因でのみ性能向上せざるを得なくなってきました。
アーキテクチャの改良とは、キャッシュの改良や分岐予測精度の向上でパイプラインをスムーズに流すことによるIPC向上、命令レベル並列処理の並列性抽出度を向上させることによるIPC向上と、SIMD演算命令のデータレベル並列処理で浮動小数点演算を高速化することによるFLOPS/cycleの向上です。
このような背景によりクロック周波数の向上に頼らずアーキテクチャの改良のみで性能向上するしかなくなったため、シングルコアの大幅な性能向上は非常に難しくなってきました。
そこで、もしアプリケーションにスレッドレベル並列性が十分に存在するならば、4GHzのコアを2つ用意してアプリケーションを2つに分割して実行すれば擬似的に8GHzのシングルコアと同じ性能を実現できる、という妥協案が採用されました。
8GHzのクロック周波数を4GHzに下げると電圧は1/2で済むため電流も1/2になり消費電力は1/4になります。消費電力が1/4になったコアが2つということは全体として消費電力は1/2になっています。これが「コアを増やす」手法のメリットです。8GHzのコアを1つ用意するよりも、4GHzのコアを2つ用意するだけで消費電力を1/2にできてしまいます。
「並列性が十分に存在するアプリケーションなら、コア数を増やして消費電力を下げつつMIMDで高速化しよう」というのがコア数を増やす一つの動機です。
ただ問題なのは、この前提条件である「アプリケーションにスレッドレベル並列性が十分に存在するならば」という部分が重要で、実は世の中のほとんどのアプリケーションはこの前提条件を満たしていません。これが「コア数が2倍3倍になっても性能が2倍3倍にならない」理由です。
一方でシングルコアの性能が2倍3倍になると「アプリケーションにスレッドレベル並列性が十分に存在するならば」という前提条件を満たしていても満たしていなくてもどちらでも2倍3倍と高速化できるため、できる限りシングルコアの性能(1コアあたりの性能)を向上することが望ましいです。
このような事情から、アーキテクチャ改良で少しずつシングルコア性能を上昇させることを優先しつつ、これ以上大幅なクロック周波数増加が望めないため同時にマルチコア化も組合せてきたのがARM、Intel、Apple製プロセッサです。
しかし、AMD Ryzenの場合は少し事情が異なります。
Ryzenのようにコア数を増やすことで見かけ上の性能を増やしていくことが2017年から流行しているのは、コア数の増加はカタログスペックでアピールしやすいメリットがあるためです。コンピュータ・アーキテクチャ分野に詳しくない人は「コア数が2倍3倍と増えると性能も2倍3倍になる」と勘違いしてくれるため、Ryzenを買った後で「並列性が高い特殊な用途でないと性能は出ない」と気づいても返品できないことからメーカーのAMD側としてはメリットがあることになります。
特にCinebenchのように実際の用途では現れることのない多数のスレッドを同時に実行し多数のコアを使い切るというかなり特殊な用途ならRyzenは最適です。
実際の用途ではほとんど登場することのないCinebenchで実行される特殊な処理や、将棋の局面探索、同時に多数の動画エンコード等をメインでやる人はこのRyzenを選んで間違いありません。並列性を十分に活かせるからです。しかし、Excel・Word・ブラウザでウェブ閲覧(Youtube閲覧)などの一般的で実際的なPC用途のように、1コアあたりの性能が重要である汎用性を重視するならIntel Coreをおすすめします。しかもIntel Coreならスレッドレベル並列処理性能も同時に高いため、動画エンコードでも高速です。
シェアが低い少数派のAMD Ryzenが一部で強く支持される理由
Ryzenが実力以上に持て囃されている理由は、Intelの一強独壇場を打ち崩す役割を果たし、高止まりしているCPU価格を引き下げる効果が期待されていることにあります。これは合理的な理由です。
他には合理的な理由ではなく、感情的な理由で業界第1位より第2位を応援したいという判官びいきもあります。世の中には「1位」「一強」「多数派」を嫌う人達が一定数存在するためです。CPUのシェアは個人向けのゲーム用途でもIntel:AMD=70:30、官公庁や大企業等の法人向けのシェアだとIntel:AMD=100:0になってしまいAMDはCPUの採用数で少数派です。AMD Ryzenは「弱い企業側の味方をしたい」という価値観を持つ人達から強く支持されています。
RyzenとIntel Coreプロセッサの性能比較評価手法
性能評価と比較は次のように行います。
2017年に発売されたZen世代Ryzen(Summit Ridge)プロセッサとIntel Coreプロセッサとの比較は、同じ2017年度に発売された第8世代Intel Core(Coffee Lake)プロセッサを対象に行います。
2018年に発売されたZen+世代Ryzen(Pinnacle Ridge)プロセッサとIntel Coreプロセッサとの比較は、同じ2018年度に発売された第9世代Intel Core(Coffee Lake Refresh)プロセッサを対象に行います。
2019年5月に発売されたZen2世代Ryzen(Matisse)プロセッサとIntel Coreプロセッサとの比較は、2020年において発売された第10世代Intel Core(Comet Lake)プロセッサを対象に行います。
2020年11月に発売されたZen3世代Ryzen5000シリーズ(Vermeer)プロセッサとIntel Coreプロセッサとの比較は、同じ2020年度において発売された第11世代Intel Core(Rocket Lake)プロセッサを対象に行います。
2022年度に発売されるZen4世代Ryzen7000シリーズ(Raphael)プロセッサとIntel Coreプロセッサとの比較は、同じ2022年度に発売の第13世代Intel Core(Raptor Lake)プロセッサを対象に行います。
また、Intel Coreプロセッサには内蔵グラフィクス(iGPU:integrated GPU)が搭載されており、内蔵グラフィクス非搭載のZen3世代までのRyzenとの比較では、内蔵グラフィクスを搭載している分だけ汎用コアに割り当てることのできるチップ面積が減少することになりIntel Core側にハンデがあることになります。しかしこれはRyzen側に下駄を履かせる効果があるため、企業規模(総資産額、純資産額、設備投資額)で劣るAMDのRyzenプロセッサを不利にしすぎないための配慮になります。
そしてカタログスペックではなく実効性能で性能の優劣を比較します。価格においては定価ではなく実勢価格が重視されるのと同じで、車においてカタログ燃費よりも実燃費が重視されるのと同じです。CPUを購入したユーザが実際使ってみて性能がどの程度でるのかが最も重要だからです。
ベンチマークにおいては並列化できないシングルスレッドの性能を重視するものや、スレッドレベル並列性が高いマルチスレッド性能を重視するものもあり様々です。シングルスレッドの性能を重視するベンチマークを使うとIntel Coreが有利になってしまいますし、マルチスレッド重視のベンチマークだとAMD Ryzenが有利になります。
そこで今回掲載しているベンチマークは実際の用途に近い処理で実効性能を計測するベンチマークに加えて、スレッドレベル並列性が無いシングルスレッドの性能、多数のスレッドを各コアに割当てたマルチスレッドの性能を測定するベンチマークも掲載しています。
第4世代Ryzen5000シリーズ(Zen3マイクロアーキテクチャ採用Vermeer)とIntel Coreプロセッサをベンチマーク評価
第4世代Ryzen5000シリーズ(Vermeer)プロセッサとIntel Coreプロセッサをベンチマーク評価して比較します。第4世代Ryzenのベンチマークについては別の記事で詳細に網羅的に掲載していますが、ここではそのダイジェスト版として掲載します。
本記事の冒頭にも記載した通り、第4世代Ryzenから見て最も発売日が近いIntel Coreプロセッサは第11世代Intel Core(Rocket Lake)プロセッサであるため第11世代Intel Coreの各プロセッサと比較していきます。
第4世代Ryzenは2020年11月時点で主に4モデルしか設定されませんでした。第4世代Ryzenを生産するTSMCが逼迫し主要顧客のARM,Apple,Qualcommが優先されたことに加えて、歩留まりの悪さのため生産数を確保できず設定されたモデル数も大幅に減ったことになります。一応他にも低クロック版が存在しますがOEM供給のみに限られており、それが組込まれたPCは殆ど流通していません。
Ryzen 9 5950XとIntel Coreプロセッサを比較
まずは第4世代Ryzenで最も重要なフラッグシップモデル、Ryzen 9 5950XをIntel Coreプロセッサと比較していきます。
・Ryzen 9 5950X vs. Core i9 11900K
Ryzen 9 5950Xは第4世代Ryzenで最高峰という位置づけのため、第11世代Intel Core(Rocket Lake-S)でフラッグシップのCore i9 11900Kと第一義的に比較することになります。
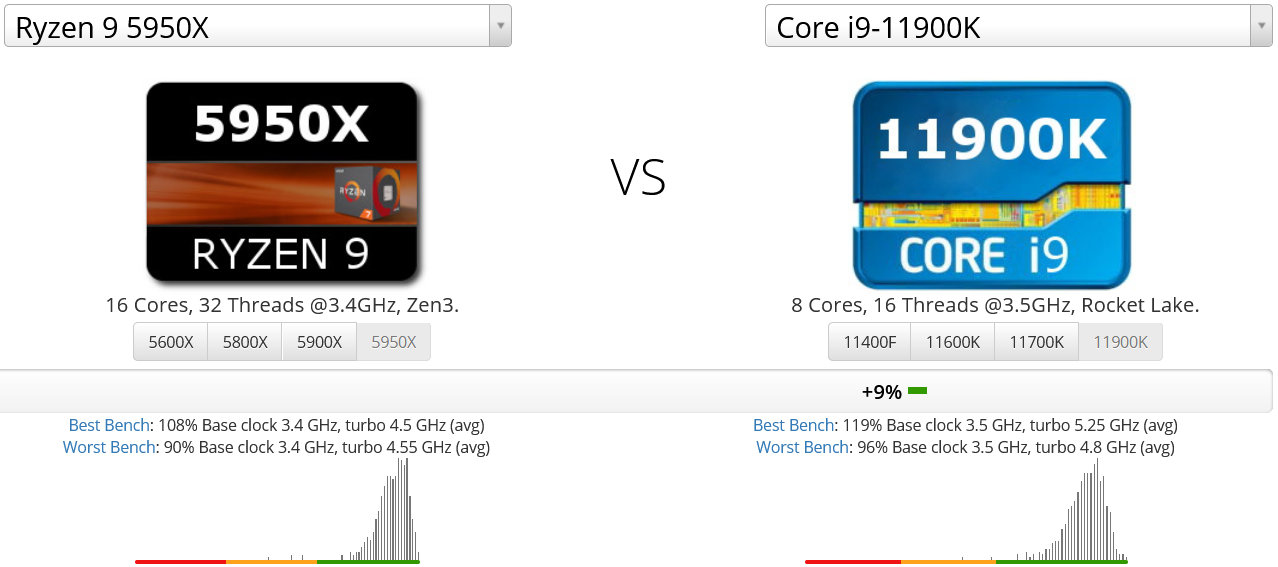
このように8コアのCore i9 11900Kに対して、16コアのRyzen 9 5950Xが敗北する結果です。「コア数が2倍でも性能は2倍にならない」といった部分について本記事で何度も繰り返し触れてきましたが、その通りになっている実例です。
・Ryzen 9 5950X vs. Core i5 11500
実はRyzen 9 5950Xを打ち負かすにはCore i9 11900Kほどの強力なCPUは不要です。6コアかつ低クロックなCore i5 11500で十分です。
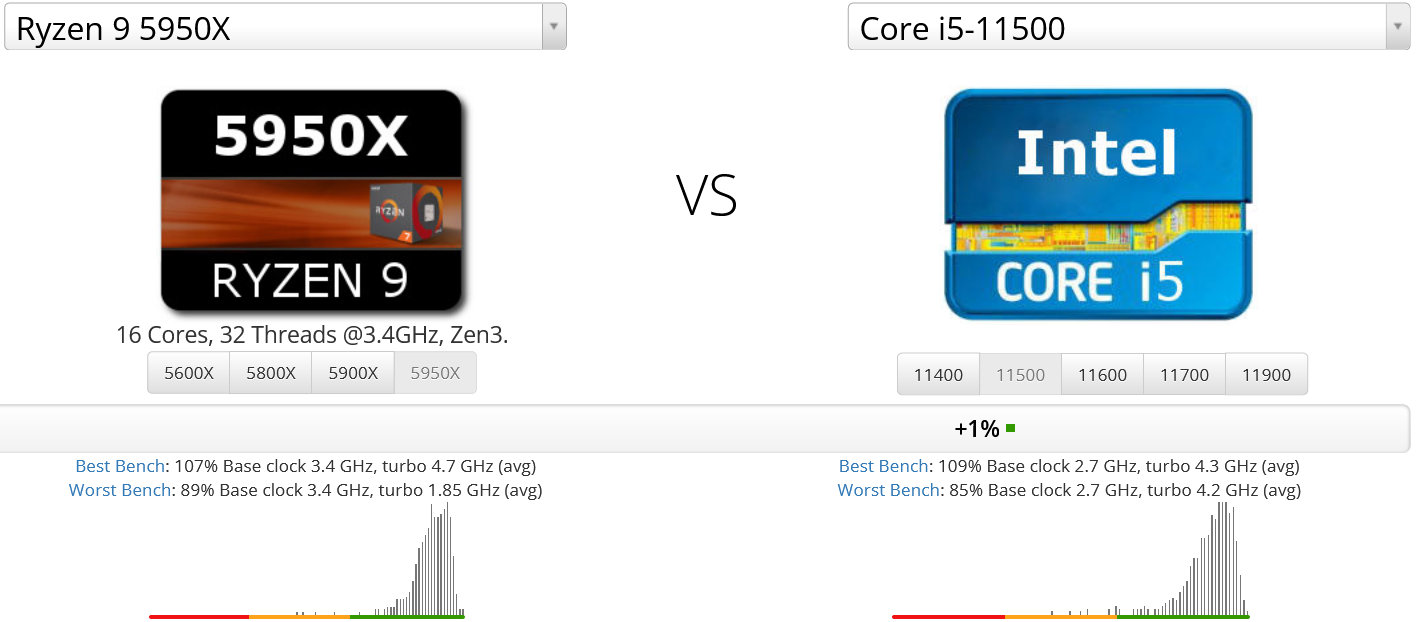
このように+1%の性能差で、Ryzen 9 5950Xに対しCore i5 11500が勝っています。たった6コアかつ高クロックでない無印の65WプロセッサにRyzen 9 5950Xが負けてしまったのは、Ryzen 9 5950Xの存在が精神的支柱のAMDユーザにとって大きな屈辱です。
Ryzen 5 5600XとIntel Coreプロセッサを比較
第4世代Ryzenの中で6コアを担当するのがRyzen 5 5600Xです。Ryzen 5 5600Xは単に6コアという位置付けだけではなく、第4世代Ryzenの6コアの中で最も高クロックなモデルという位置付けも兼ねています。
・Ryzen 5 5600X vs. Core i5 11400F
第11世代Intel Core(Rocket Lake)の6コアモデルはCore i5 11600K, 11600, 11500, 11400と4グレード存在しますが、その中で最も低グレードで低クロックなCore i5 11400Fと比較してみます。
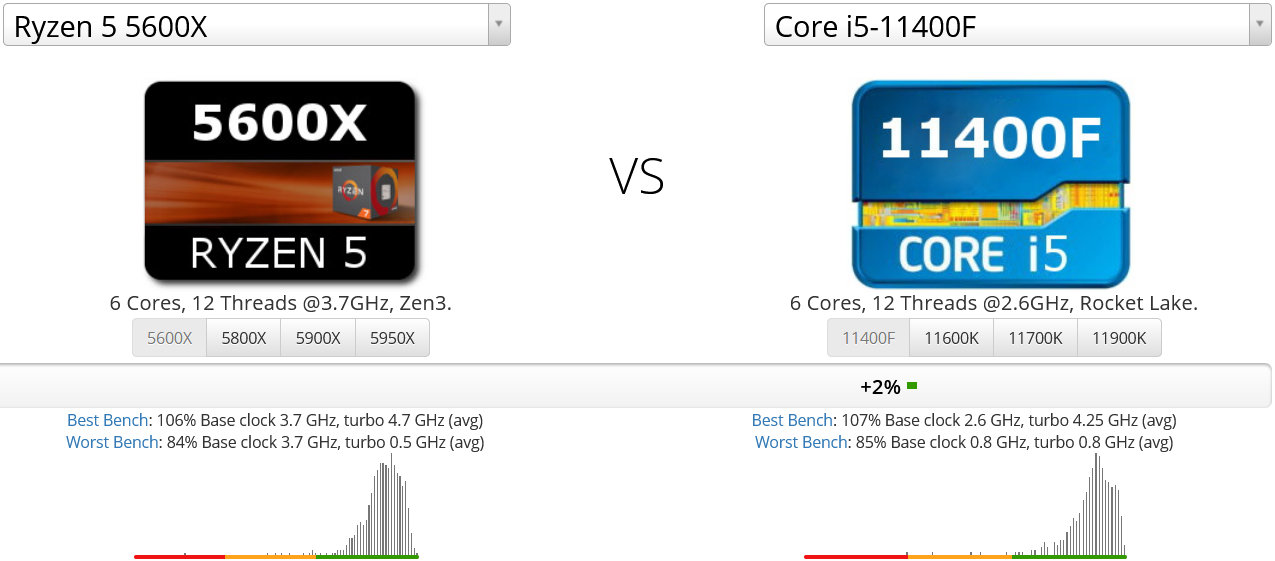
このようにCore i5 11400Fに対して2%の性能差でRyzen 5 5600Xが敗北してしまっています。第4世代Ryzenの6コアモデルの中では最も高クロックなRyzen 5 5600Xであっても、第11世代Intel Coreの6コアモデルの中では最も低クロックなCore i5 11400Fに負けてしまっているのは、Zen3マイクロアーキテクチャを採用した第4世代Ryzenにとって屈辱だと言えるでしょう。
コア数が多くてもアプリケーションに並列性がなければ宝の持ち腐れになる
このようにRyzenが全敗しIntel Core全勝の結果になった理由は簡単です。Ryzenの方が1コアあたりの性能が低いからです。RyzenのようにIntel Coreの2倍のコア数である8コア16コアレベルでいくらコア数を増やしても、実行するソフトウェアの並列性がない限りは実効性能を上げることはできません。
これは1964年に世界初のスパコンが出来た時から現在に至るまで、大学の研究者から企業の技術者も頭を悩ませる古典的な問題です。いくら並列実行するためのコア数が増えてもそれを使いこなせるソフトウェアがなければ宝の持ち腐れです。Amazonの和書で「並列処理」のようなキーワードで検索して出版年を遡ってみるととてつもなく古い本が出てきてしまうくらいです。。
今回のベンチマークが示しているのは結局世の中の大半のソフトウェアは1コアのみで動くようにできているということです。つまりシングルスレッドでプログラミングされていることを意味します。なぜマルチスレッド化して実装されていないかというと、データの依存性で並列化したくても原理的に並列化できないからです。これはAmdahlの法則を知っている人なら理解が早いと思います。コア数をいくら増やしても並列化できない部分は高速化できないため、コア数を2倍3倍と増やしても性能は2倍3倍とスケールせず性能向上は頭打ちになってしまうという法則です。
一般人の用途で多数のコアを有効活用できるのは動画エンコードくらいです。しかし日頃から動画エンコードしかひたすらやっていない人は極々一握りであり、ほとんどの人はブラウザでウェブサイト閲覧をしていたり、Amazon Prime VideoやYoutubeを観ていたり、レポートを提出するときはWord(一部の学生はTeX)で文書作成をしているわけです。そのような用途では1コアあたりの性能が高いIntel Coreの方が優秀です。
内蔵グラフィックス十分な人にとってはIntel Coreシリーズの方がお得
Ryzenは内蔵グラフィックスを搭載したことでコアの数でもIntelに負けてしまう
またIntel CoreシリーズからみてRyzenが異様だったのは内蔵グラフィックスを搭載していなかったことです。
AMD RyzenではIntel Coreにコア数の多さだけでも追いつくために、本来内蔵グラフィックスを乗せる部分のチップ面積を汎用コアに回しました。内蔵グラフィックスをCPUチップ上に載せないかわりに、その空いた面積を汎用プロセッサに振り分けたわけです。
内蔵グラフィックスをCPUチップ上に搭載してしまうと、その分だけ汎用プロセッサに割り当てる面積が減り、汎用プロセッサの性能を高くできないからです。
一方で、Intel CoreはこのAMD Ryzenとは全く逆のことをしています。
Intel Coreプロセッサは世代が重なるごとに内蔵グラフィックスのチップ面積を増やし着実に強化してきました。IntelとAMDは向いている方向が全く逆です。
なぜIntelは汎用プロセッサ用のチップ面積を減らしてまで内蔵グラフィックス性能を年々上げているかというと、NVIDIA GeForceやAMD Radeonから顧客を奪って、内蔵グラフィックスだけで間に合うようにすることをIntelは狙ってるからです。
実はIntel Coreプロセッサの汎用4コア分の面積が、Intel UHD Graphics(内蔵グラフィックス)用のコア面積とほぼ同じということはあまり知られていないようです。
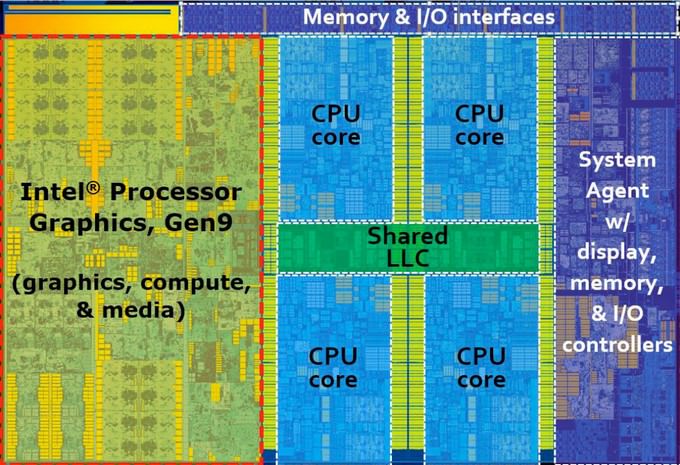
これはSkylakeマイクロアーキテクチャの4コアモデルのチップです。
一番左の部分が内蔵グラフィックスです。そして真ん中の5つの青い長方形がある部分がCPUの中枢とも言える汎用4コアの部分です。
このようにみると汎用プロセッサとオンボードグラフィックスの面積がほぼ同じだということがわかります。
Intelの場合、初代のIntel Coreでは内蔵グラフィックスの面積はこんなに大きくなく、Intelは内蔵グラフィックスに力を入れず冷遇していました。気休め程度に「ディスプレイが取り敢えず映りさえすればいい」程度の認識しかIntelにはありませんでした。
しかし、現在のIntel Coreプロセッサではチップ面積の大半をグラフィックのために割いています。
なぜそのようなことをするかと言えば、ゲーム以外の用途として使う人にとっては画面出力のためだけに高価なグラフィックボードはオーバースペックすぎて不要だからです。だからといって、Youtube再生や簡単な3Dグラフの描画程度でもたつくのは困ります。
そこで拡張グラフィックボードがなくても、そこそこのグラフィクス性能を確保するために、最近のIntelはNVIDIA GeForceやAMD Radeon潰しのために、CPU上のオンボードグラフィクスに注力しているわけです。
次にRyzenのチップを見てみます。

左と右にそれぞれ1つずつ、合計2つ見える横長の長方形がRyzenの汎用コアです。
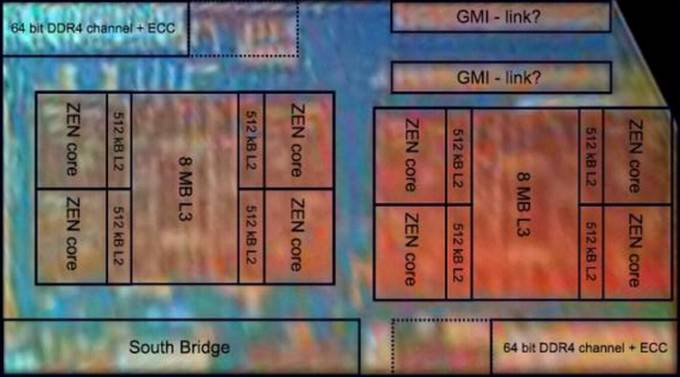
このように片方の長方形で4コア、もう片方の長方形で4コアで合計8コアにしています。
この図にはグラフィック部分が見当たりません。それは当然であり、第1世代1000シリーズから第4世代5000シリーズまでのRyzenでは一切グラフィックスを載せていないからです。Ryzen APUのように内蔵グラフィックスを載せたモデルは一応ありましたが、内蔵グラフィックスを載せたせいでコア数が半減しており主流ではありませんでした。
グラボを別途お買い求めくださいというコンセプトなのがRyzenです。
なぜここまでしてRyzenではオンボードグラフィックスを削ったのかと言えば、それは単なるRyzenのコンセプトだけではありません。
Intel Coreに太刀打ちするために仕方なく、Ryzenではオンボードグラフィックスを削ったのです。
このような事実を認識すると、第3世代Ryzen APUになってもいまだにRyzen APUが4コア止まりである理由がよくわかると思います。Ryzen APUはオンボードグラフィクスを搭載したRyzenシリーズです。APUでないRyzenはコア数が8以上なのにAPUになると第1世代からずっと4コアのままです。だからこそ汎用コア数を増やすためにはオンボードグラフィクスを削らざるを得なかったことを、AMD Ryzenが自ら証明してくれています。
理由1:内蔵グラフィックスを削減して汎用コアにチップ面積をまわさないとIntelに太刀打ちできないから
Zen世代(Ryzen1000シリーズ)~Zen3世代(Ryzen5000シリーズ)のRyzenは内蔵グラフィックスをCPU内部に搭載していません。Zen4世代(Ryzen7000シリーズ)のRyzenから内蔵グラフィックスを搭載するようになりましたが、そのせいで汎用コア数でIntel Coreに負けてしまう結果となりました。
Ryzenでは内蔵グラフィックスを搭載しない代わりに、その空いたチップ面積汎用プロセッサ部分に割り当てることによって、AMDは技術力ではIntelに敵わないから汎用コア用のチップ面積を増やすことでなんとかIntelの背中に追いつこうとしてきました。
Intelプロセッサでは内蔵グラフィックスと汎用コアで丁度同じくらいの面積を分け合ってきたものの、Ryzenでは内蔵グラフィックス用の面積はゼロだったわけです。
Ryzenでは内蔵グラフィックスをCPU上に載せない代わりに4コア8スレッドの汎用コアをもう1セット追加してダイ1枚あたり8コアを実現しなんとかIntel Coreと勝負しようとしたものの、やはりベンチマークでは負けてしまいました。Core i7どころかCore i5にすら負けてしまった形です。
でもAMDの企業規模から言えば一強のIntelに対してそこそこ健闘した方だとは思います。
第1世代Ryzenが発売された2017年度のAMD売上高は53億2900万ドル、第2世代Ryzenが発売された2018年度のAMD売上高は64億7500万ドルでした。
一方でIntelはの売上高は2017年度が627億6100万ドル、2018年度が708億4800万ドルです。これは売上高で、純利益だとさらに差は広がって100倍程度Intelが上になってしまいます。このような企業規模の差がありながらもAMDは頑張って努力はしたほうです。
理由2:そもそもAMDはNVIDIAと並ぶグラボチップメーカーなので内蔵グラフィックスをRyzenに搭載してしまうとAMDの自社GPU(グラボ)が売れなくなってしまうから
AMDはCPUではIntelに大きく水を開けられていますが、グラフィックボードではそこそこ健闘しています。NVIDIAという巨人がいるものの、グラフィックボードは価格がそもそも高いので稼ぎ頭です。
もしグラフィックボードが売れなくなってしまうとAMDとしても困ります。
例えばRyzenに内蔵グラフィックスを内蔵してしまうと、ゲーマーでない限りは内蔵グラフィックスで十分なのでグラフィックボードを買おうとしません。そうなるとグラフィックボードを売りたいAMDとしては好ましい展開ではありません。
Ryzenはあくまでも汎用プロセッサ。グラフィックプロセッサが欲しいなら別途グラフィックボードを購入する方向に持っていくほうがAMDとしても望ましいということです。
その後Intel CoreがAMD Ryzenの汎用コア数と並んでしまったことで、「コア数の多さだけはIntelに対しマウントを取る」といったAMDの戦略が通用しなくなってしまいました。そこでAMD RyzenのメインストリームCPUでも内蔵グラフィックスを搭載しないわけにはいかず、Zen4世代からは内蔵グラフィックスを搭載するようになりました。しかしそれによってRyzen7000シリーズはRyzen5000シリーズから汎用コア数が伸びないといったジレンマに陥っています。内蔵グラフィックスを搭載したことで汎用コアを増やせなかったということです。
プロセスの微細化は消費電力やコア数では有利になるが動作クロックの向上では不利 リーク電流の増大が原因
まずは事前知識として以下の記事を読んでおきましょう。東京大学教授の解説を引用した記事であり極めて理屈的です。学術的なことが論拠になっているので、理屈より感情でAMDを応援したい低学歴なAMD愛好家にとっては非常に読むのが苦痛でしょうが、現実を正しく認識するには良い記事です。
>「7nmの半導体」に7nmの箇所はどこにもない
>2019年7月19日の日経新聞の「経済教室」に、東京大学生産技術研究所の平本俊郎教授が執筆した『データ駆動社会の展望(中) 半導体、設計思想の変革を』という解説記事が掲載された。
>東大の平本先生は明快に、「実は7ナノメートルプロセスのチップ上に7ナノメートルサイズの箇所はどこにもない」と書いている。
https://news.livedoor.com/article/detail/17044867/
プロセスの微細化にはメリットとデメリットがあります。本項目で解説する「リーク電流」が顕在化するまでは、プロセスの微細化のデメリットはほとんどなく「低消費電力化」「チップ面積の縮小による歩留まり改善」「スイッチング性能の向上」というメリットだらけであり、デメリットは「配線遅延の悪化」くらいでした。しかしリーク電流の問題化が顕在化してくると、微細化で低消費電力化と面積の縮小は達成できても回路性能の向上は鈍ってきました。
実際に7nmプロセスを採用したAMD Radeon VII(3840コア)は12nmプロセスのNVIDIA GeForce RTX 2070(2304コア)に大敗しています。
プロセスの微細化の第一のメリットは動作クロックを維持したまま電圧と電流を下げることができることによる低消費電力化です。
AMDにとっても最も関心があるのは「低消費電力化」です。12nmプロセスを採用した第2世代Ryzenの動作クロックを維持したままで、7nmプロセスにするだけで消費電力が下がるからです。
ここで「7nmプロセスにして消費電力が下がって終わり」、だと「とにかく高性能なCPU」を志向する自作PCユーザに魅力的に映りません。そこでこの余裕のできた消費電力を「コア数の増加」または「動作クロックの上昇」に割り当てるのがAMD Ryzenの戦略です。
第3世代Ryzenでは7nmプロセスに移行してできた消費電力の余裕を「コア数の増加」に割り当てました。そのためコア数が12nmプロセス第2世代Ryzenの8コアから16コアになっているわけです。
しかしその引き換えとして動作クロックの引き上げには失敗しました。つまりベースクロック4GHz台、ブーストクロック5GHzの大台は第3世代Ryzenでは諦めたわけです。これはNVIDIA vs. AMDでも同じで、1コアあたりの性能ではNVIDIAに勝てないということでAMD Radeonではコア数の多さでマウントを取っています。
実際に2019年5月の第3世代Ryzen発表時に、AMDが自ら「今回の7nmプロセスは以前の12nmプロセスと比較して半導体回路としての性能は上がっていない。しかし消費電力は下がった。性能向上はアーキテクチャの改良で実施した」と表明しています。
さらにもっと重要な事実があります。これは2007年以前からIEEEやACM等のコンピュータ・サイエンス学会論文誌で指摘されていたことですが、「微細化が進むとリーク電流が増加するため動作クロックを引き上げることが難しい」という大きな問題があります。
半導体というのはゲートの電圧を変化させることで、ドレイン~ソース間の電流のONとOFFのスイッチを実現できる素子です。しかし半導体の微細化が進むと、演算を行っていない(スイッチング動作していない)OFF状態の半導体でも電流が流れてしまう「リーク電流」が急増します。何もしていなくても流れてしまうのでstatic電流ともいいます。
オーバークロックするときになぜ電圧を上昇させるかというと、高い動作クロックの実現のためには高周波成分を減衰させないことが必要であり、高周波成分を減衰させないためには高い電圧が必要だからです。
つまりCPUの動作クロックを上昇させるということは電圧を上昇させることが必ず伴います。しかし微細化が7nmのように進んでくると、高い電圧はリーク電流を急増させてしまいます。微細化が進むということは絶縁性が低くなることを意味するので、絶縁が弱いのに電圧を上昇させてしまうとリーク電流が大きく増えてしまう結果になります。消費電力は電流の大きさの2乗に比例するため消費電力も急増してしまいます。結果的に発熱量が増えて半導体のスイッチング性能が低下します。半導体は回路をON、OFFすることでBool代数論理回路を実装しているわけですが、発熱量が増えるとこのスイッチング性能が悪化します。「冷却ができないと性能が低くなる」ことは多くの人が経験則で知っていると思いますが理論的には以上のように説明できます。
よって7nmプロセスのように微細化が進んだ半導体では動作クロックを上げることが非常に難しく、必然的に「1コアあたりの性能が低いCPU」ができあがってしまいます。
実際、7nmプロセスを採用したRadeon VIIは12nmプロセスのRadeon RX Vega 64と動作クロックはほぼ同じでした。
プロセスの微細化は半導体の「スイッチング遅延」を短縮し改善する効果はあります。各社も低消費電力化に加えてこのメリットを狙って微細化をしています。しかし「配線遅延」は微細化によりむしろ悪化することが明らかになっています。この両者を足したのが「伝搬遅延」であり(伝搬遅延=スイッチング遅延+配線遅延)、この伝搬遅延を短縮することがプロセッサの高速化に必要です。
7nmへの微細化による配線遅延の悪化でトータルとしての伝搬遅延が改善しなかったことが、「TSMC7nmで半導体回路自体の性能は上がっていない」とAMDが公式に認めた理由です。つまり微細化のメリットではなくアーキテクチャの改良で性能向上したことになります。
さらにこの微細化によるスイッチング遅延の低下のメリットも、先程の「クロック上昇→電圧上昇→リーク電流増大→高消費電力化→スイッチング性能低下」が発生してしまうと打ち消されてしまいます。第3世代Ryzenで5GHzが達成できなかった理由はこういった事情によるものです。
7nmや5nmプロセスといった微細化は、動作クロックを上昇させて1コアあたりの性能を向上させる用途では不向きです。微細化されたプロセッサが向くのは、512コアのように非常に多くのコアを用意して各コアの動作周波数を1GHzのように非常に低くするサーバ用途です。またはTDP15W、TDP5Wのような低消費電力を志向するラップトップやスマートフォン等のモバイル向けの用途です。低消費電力こそプロセス微細化のメリットそのものだからです。
よって、消費電力はおかまいなしに絶対性能のみを追求する傾向が強い「自作PCユーザ」からすると、今回の第3世代Ryzenは1コアあたりの性能が大して向上せず、PUBGのような1コアに大きな負担のかかるFPSゲームをプレイするプロゲーマーから再び見向きされないプロセッサになってしまったということです。
まとめ:
Ryzenが有用なのはCinebenchのようなマルチスレッド特化型の机上の空論ベンチマークだけ
ウェブサイト閲覧、ゲーム、Youtube再生、Word・Excel文書作成などの実際的な用途ならIntel Coreが優秀
私から見ればRyzenプロセッサは「大量の非圧縮音楽ファイルをFLACに圧縮する」といったマルチメディア並列処理をひたすら実行する特殊な限られた人向けのCPUです。
ウェブサイト閲覧をする、ゲームをする、Youtubeを再生する、Excelで簡単な表を作ったりWordでレポートを作成するといった用途ならIntel Coreが優秀です。
また学生等で機械学習を専門にする研究室に配属された場合や機械学習系の科目を履修した場合、または個人で機械学習(世間で言ういわゆるAI、ディープラーニング)をやる場合はIntel Coreがおすすめです。Visual Studioで.NetFrameworkを使ってプログラミングしたりPythonを使う人でもIntel Coreがおすすめです。.NetFrameworkなら自動的にIntel Math Kernel Library(MKL)を使うように中間コードを変換し実行してくれるため数値計算をする人でもIntel Coreがマッチします。当然native C++で書く場合にもIntel Coreのほうが性能が高くなります。
動画や音楽(ハイレゾのような高サンプリング周波数のデータ)といったマルチメディアデータのエンコード処理をひたすらやるのなら、Intel CoreではなくAMD Ryzenが十分いい選択になると言えます。
ただ動画の編集自体はIntel Coreが優秀です。編集作業では1コアあたりの性能の高さが重要なためです。動画を丁寧に編集する必要があるYoutuberや、長いTwitch動画を切り抜いてYoutube投稿用の動画を作る編集をするストリーマーにはIntel Coreの方がいいです。
Ryzenがオンボードグラフィクスを削ったことには目を瞑って、Ryzenの1コアあたりの性能がIntel Coreより高ければRyzenにも存在価値はありました。しかし実際はRyzenがIntel Coreに性能でも負けてさらにオンボードグラフィックスが付いていないとなると、合理的判断をするならばIntel Coreを選ばざるを得ません。感情で判官びいきでもしない限りRyzenの選択はありません。
しかしRyzenには「型番のグレードが同じならIntel Coreより安い」といった最終手段のメリットがあります。つまりCore i9 12900KよりもRyzen 9 5900Xが安いといったメリットです。「性能は高いけど価格も高いIntel Core」「性能は低いけど価格も安いAMD Ryzen」といった棲み分けは、実はIntelとAMDがRyzen登場以前からずっと実施してきた業界棲み分けの構図と全く一緒です。
最近AMDは「お金の無い人向けのローエンドのAMD Ryzen」といったイメージを払拭したがっており、Apple社のような高付加価値な企業イメージに塗り替えたいと考えているようですが、実際は今でも「Intelは高くて選べずお金を買う人がない人が選ぶのがAMD」になってしまっているのが現状です。
Intel vs. AMDの経過
初代のAMD Ryzenは2017年に発売されましたが、その当時からAMDは常に世の中の潮流とは逆の判断をしてしまい未だに不遇なCPUです。ある株を買うとその株が暴落してしまう”逆神”のような特性を持つのがAMDだと言ってもいいでしょう。その経過は以下の通りです。
本来はRyzenがIntel Coreより優位に立つはずだったゲーム分野
AMD Ryzenは2016年にZenアーキテクチャの発表があったのが初出でした(発売は2017年)。その2016年の発表当初から8コアになることが発表されており、当時4コア止まりだったIntel Coreの4コアの2倍であることが大きく注目されていました。
これを受けて海外のPC系メディアでは「ゲーム用CPUの完成形が現れた」と大歓迎していました。実は2016年以前に主流だったゲームでは1コアあたりの性能の高さは不要で、とにかくコア数が多くスレッドレベル並列処理性能が高いほうがゲーム用途では有利でした。これまで登場してきたコンシューマゲーム機も1コアの性能を追求しておらず動作クロックの低いコアを大量に採用したものです。
そのためZenアーキテクチャを製品化したRyzenは”gaming cpu”として持て囃されていました。Ryzenは2017年3月2日に発売された第1世代のRyzen 7の時点で8コアを実現しており、実に当時のIntel Core i7(4コア)の2倍のコア数を実現していたからです。
しかし、Ryzen発売から間もない2017年3月24日にPUBGというゲームが登場します(まだこの頃はアーリーアクセス、ベータ版)。
当初多くの人は「何このゲーム?」といった扱いをしていたのですが、2017年夏頃には爆発的にヒットしてしまい、まだPUBGが正式版でないにも関わらずTwitchやYoutubeの配信や実況でPUBGが主流となり、BTO PCショップも「PUBGに最適」を謳ったPCをメインに据えてしまうほどの需要の大きさでした。「ゲーミングPCといったらPUBG用途前提」と言わんばかりの勢いであり、それまで低調だったBTO PC業界も活況になりました。PUBG流行による大きな貢献は、一般家庭にもPCゲーム向けのハイスペックPCを普及させたことです。
さらにPC業界にとって幸いだったのはPUBGが非常に負荷の重いゲームだったことです。未だに人気で息の長いゲームとしてLoLがありますが、LoLはPCのスペックが低くてもいいので高性能CPUや高性能GPUは不要でした。そのため高価なIntel Coreや高価なNVIDIA GeForceよりも、安価なAMD RyzenやAMD Radeonでも十分だったわけです。一方でPUBGは非常に高負荷でハイスペックゲーミングPCが必要だったため、高性能で高額なBTO PCが注目されこれがPC業界の活況に繋がりました。
そしてGPUのみならずPUBGでは「1コアあたりの性能が高いCPUでないとフレームレートが下がる」ことが明らかとなったためIntel Coreがプロゲーマーやストリーマーから積極採用されることになってしまいました。実際にTwitchで常に上位表示される日本国内の著名ストリーマーも2017年当時からIntel Coreを使用しています。
PUBGでは各オブジェクトの同期処理をたった1つのスレッドで実行しています。つまりオブジェクトの数が増える(狭い範囲に敵・味方が集まる)と同期をとるべきオブジェクトが急増し、重い処理が1コアに集中してしまうため「1コアあたりの性能が低いCPU」だと大きくフレームレートが下がる要因になります。
そのため1コアあたりの性能が低いRyzenはフレームレートが伸びずPUBGゲーマーから見向きされなくなり、本来覇権を握るはずだったゲーム用CPUからはじき出されることになってしまいました。
実はPUBGを始めとしたバトロワ系FPSゲームが例外なだけで、本来ゲームは1コアあたりの性能が低くてもより多くのコアがあったほうが有利なのは前述した通りです。
なのでPUBGのような例外的な闖入者が2017年に現れなければゲーマーからRyzenが大量採用されるのは普通にあり得ることでした。それがたまたま初代Ryzen発売月の2017年3月にPUBGがリリースされ大流行してしまい、その後ApexLegendsのような派生系ゲームが大量に登場してきてしまってプロの間でもストリーマーの間でもPUBGのようなFPSゲームが大会でも配信でも主流となってしまったのは本当にタイミングが悪く、Ryzenにとっては巡り合わせの悪い不幸だったとしか言いようがありません。
AMDが対NVIDIAとしてAIに注力するため、全社的に従業員を1000人超の削減と発表
「CPU軽視」の失望からAMD株が暴落しIntel株が高騰する結果に
2024年11月にAMDが人員削減を発表し、普通なら人員削減は株価上昇材料になるのが普通にも関わらずAMD株は3%超のマイナスとなり暴落しました。他方でIntel株が3%の上昇。NVIDIAを始めとして割高が指摘される半導体株の地合いが悪い中での上昇となりました。
AMDが人員削減を発表したのは「AIに注力するため経営資源をAIに集約する」ためです。NVIDIAが機械学習向けプロセッサで一強の中で、AIブームの今が大幅に成長する好機だとAMDは判断したようです。
このAMDの判断が、結果的にIntelの株価を3%引き上げました。これはAMDがPC向け汎用プロセッサへの関心を低減させ、アクセラレータを始めとした機械学習向けプロセッサに経営資源を傾ける決断だとみなされたためです。
これはAMD株を保有しているAMD愛好家が多いAMD株ホルダーにとって「CPU分野でIntelのシェアを奪って欲しいからAMD株を持っていたのに,NVIDIAからシェアを奪う戦略に出た」と”失望”だったようでAMD売りで反応されたことになります。これはIntelにとっては寡占を維持できる朗報だったこともあって株高となりました。
機械学習ブームは過大評価されていていずれNVIDIAも調整に直面するでしょう。NVIDIAは体力があるので生き残るでしょうが、AMDがAIに経営資源を傾けた途端に機械学習ブームが終焉するとAMDはお得意の「逆神」を再度演じてしまうことになります。
半導体不足が顕在化した2020年以降AMDがTSMCから冷遇される理由、CPUはIntelだけで十分なため
代わりが効かないQualcomm,ARM,AppleがTSMCでは優先される
AMDは2020年以降TSMCから冷遇されRyzenの生産枠をもらえず、Ryzenの生産数を確保できない「TSMC依存リスク」に直面しています。2020年以降はテレワークの急激な拡大でサーバー用CPU、モバイル用CPUの需要が拡大しました。
しかし、そのテレワーク特需でAMD Ryzenは売れませんでした。AMDの決算を見ても相変わらずAMDの売上高や税引前当期純利益はIntelの1/10程度です。決算ほど客観的かつ公正で正直な数字はありません。
実はAMD Ryzenを持て囃してるのはPCパーツを買って組み立てるいわゆる自作PCマニアだけであり、「業界第一位のIntelが気に食わない」「Intelと比べて企業規模が1/10しかない弱い側のAMDを応援したい」という判官びいき価値観を持つ少数派が持ち上げているだけです。非常に狭い分野の極一部のユーザしかRyzenを買っていないということです。
サーバー用途やモバイル(ノートPC)用途を含めてCPUを必要とする全てのコンピュータ市場をみると、誤差程度しかAMD Ryzenは売れてません。
モバイル向けやサーバー向けのCPUではAMDのシェアは0%に等しく、Intelに対しAMDの惨敗です。実はデスクトップPCは2006年に既にピークを過ぎ、その後はモバイルPCが世界的な主流となりました。サーバー向けとモバイル向けCPUは非常に大きい市場ですが、デスクトップ向けCPUは市場自体が小さいのです。
AMD Ryzenは市場が小さいデスクトップPCの中でもさらに市場が小さい「ゲーム用デスクトップパソコン」という限られた分野でシェアが30%(PCゲーム用プラットフォームSteamの統計)に届いただけです。2017年3月のAMD Ryzen発売から既に4年も経過したにも関わらず、その結果が「パソコンゲーム用PCに限ってシェア30%」です。デスクトップPC全体では官公庁・企業等の職員・従業員向けに用意される業務用デスクトップPCが最も多く、業務用デスクトップPCではIntel一強です。業務用デスクトップPCではAMD Ryzenは皆無と言っていいでしょう。そもそもゲーム用デスクトップPCの数自体が市場全体から見たら少ないのに、その小さなゲーム用デスクトップPC市場の中でAMD Ryzenが30%に届いたところで全体から見たら誤差みたいなものです。AMDが必死にIntelに追いつこうとしてきた必死な努力は認めますが、世の中結果が全てです。
AMD RyzenはCPU市場全体で見れば非常に数が少ないのに、なぜそんな少数の生産数も確保できないのかというと、それはAMDがTSMC(台湾の半導体受託生産企業)から相手にされてないからです。
現在重要になっているのは通信用プロセッサを設計するQualcommや、組込み向けでシェアの大きいARMです。特にApple社はARM命令セットアーキテクチャを使ったApple M1プロセッサをTSMCで生産しています。
TSMCはそれらの「代わりが効かない製品を作ってる企業(Qualcomm,ARM,Apple)」向けに半導体の生産枠を割り当てました。
その結果「のけ者」にされたのがAMDです。TSMCの生産能力が落ちたのではなく、数ある顧客の中でAMDだけが優先順位を下げられただけの話です。
なぜTSMCは優先度を付けたのかと言うと、Qualcommのような企業が作るプロセッサは代わりが効きません。Qualcommの通信用プロセッサは必要不可欠であるため、無いと困るプロセッサを作っています。
しかしAMD Ryzenは無くても困らないのです。なぜなら、サーバー向けもデスクトップ向けもモバイル向けもIntel製CPUが存在するためです。TSMCからすれば「Intelのプロセッサがあるんだから代わりの効くAMDプロセッサなんか生産せずIntelに任せる」という判断をしていることになります。
AMD Ryzenが無くて困るのはAMD Ryzen信者だけでしょう。
優先順位を付けるとなるとTSMCから見てAMDは真っ先に切り捨てる対象です。TSMCから見た顧客群の中で、AMDが最下位に位置してしまったことになります。
その結果、AMDはZen3+マイクロアーキテクチャを採用し2021年度に発売予定だったWarhol世代Ryzenの開発を断念するという面白い結果も起きています。
2020年度と2021年度に発売の第11世代Intel Core(Rocket Lake-S)と第12世代Intel Core(Alder Lake-S)により、たった9ヶ月間で+45%の性能向上
2020年度末には第11世代Intel Core(Rocket Lake-S)が発売され、2021年度の11月には第12世代Intel Core(Alder Lake-S)が発売されました。それぞれの世代では+20%のシングルコア性能向上が達成されます。性能向上は比率で効くため、たった9ヶ月の間に+45%もの性能向上を達成することになります。
以下の図についての詳細は後述していますが、ここで簡単に指摘しておくとシングルコア+45%の性能向上は近年では殆ど達成されてなかった快挙です。
このようにシングルコアの性能向上は鈍化しており、最近はコア数を増やすだけで「見せかけの性能向上」をしているだけでした。多数のコアを使いきれないアプリケーションが世の中の大多数なので、コア数を増やしてもそれを使い切れるソフトウェア・アプリケーションがなければ無意味だというのがコンピュータ・アーキテクチャ(情報工学とも呼ばれるコンピュータサイエンスの一分野)において学術的に指摘されているからです。
そんな中で、Intel Coreは2020年度から2021年度にかけてたった9ヶ月の間に+45%もの性能向上を実現することになります。
なぜか高所得層、富裕層から支持されないAMD 東大同期でも実際買っているのはIntel
自分から見たら全然高所得ではありませんが、高校同期で慶應義塾理工に入って情報工学科に進学し某SIerに入った同期は既に年収1500万円に届いているものの、学生時代から一貫してIntel製CPU搭載のPCを使っています。
地方の国立大医学部医学科を出て、大学院から東大に来て博士号をとった医師(現在勤務医)もPCはずっとIntelCPUだった言っています。ただこの医師は女性であり一般人と同様に情報分野に詳しくなく「AMDは聞いたことないから選びたくない」と言っているので「一般人にAMDはなじみ薄い」ということでしょう。
また情報科学科から情報理工に進んだ同期は研究室での評価のためにAMDは使ったことはあるけれども、プライベートで買うPCはIntelにしています。
彼ら彼女らに共通するのは「今までIntel使ってきたし,あえて違うのを選んで失敗したくないから」というものです。要は考えが保守的だということです。あえてAMDを選ぶ冒険をしなくても現状維持で十分、と判断しています。
【参考文献】
AMD RyzenではどのようにIPCを向上させたのか理解するためにパイプライン、リザベーションステーション、リオーダバッファ、レジスタリネーミング、分岐予測、キャッシュコヒーレンシあたりの分野が重要です。特にZen2アーキテクチャ以降ではパイプラインのストール防止とキャッシュの関連の理解が重要になります。体系的に詳説されている通称ヘネパタで有名な以下の著書がおすすめです。

私は学部時代には原著英語版を読みました。第6版の日本語訳も出ています。
翻訳陣が豪華です。監修者はReconfigurable Computingで有名な天野英晴教授であり、実際に翻訳している人達もコンピュータアーキテクチャの専門家で、この分野では有名な坂井修一教授の研究室でPh.Dを取得した准教授が翻訳に携わっています。文系が翻訳してる日経BP出版のパタヘネよりおすすめです。パタヘネも原著は良い本なのですが、日本語版は翻訳が酷すぎるのでおすすめしません。パタヘネ日本語版はいわゆる「技術がわかってない文系が翻訳した本」です。
![コンピュータアーキテクチャ[第6版]定量的アプローチ](https://images-fe.ssl-images-amazon.com/images/I/41zAIG8lTtL.jpg)
ヘネパタは学部3~4年か学部卒業者、または修士以上の人なら簡単に読めると思います。
慶應義塾の天野研が原著6th edition(2017)の翻訳を進めていると従来からアナウンスしていましたが、ようやく2019年9月に第6版の邦訳書が出版されました。私は1つ前の第5版邦訳書も持っていますが買った当時はAmazon新品でも都内のどの大型書店でも在庫があったにもかかわらず、現在第5版はプレミアムが上乗せされた価格がついて古本市場で取引されてしまっているので第6版をおすすめします。