

2017年に発売された第1世代Ryzenですが、同じ2017年に発売された第8世代Intel Coreに負けてしまう結果となりました。
多くのベンチマークではベンチマーク結果が良くなるように最適化されてたった1つのベンチマーク結果が作られており、そのような一面的な結果だけでは実際に役立つCPUの購入を検討している人にとっては意味がありません。
実際はCPUを購入した人の数だけ異なるベンチマーク結果があります。それらを集計して平均値と分散を見ることが重要です。
実際にプロセッサを購入し使用している各ユーザーがそれぞれ、様々なマザーボードなりメモリなりを接続した普段の環境で測ったベンチマークにこそ意味があるので、実際のところどれだけ性能がでるのかという部分に焦点をあてたベンチマークの結果を見ていきます。
Ryzen 7 1800X
2017年に発売されたRyzen 7 1800Xは同じ2017年に発売されたCore i5 8600Kに敗北してしまいました。
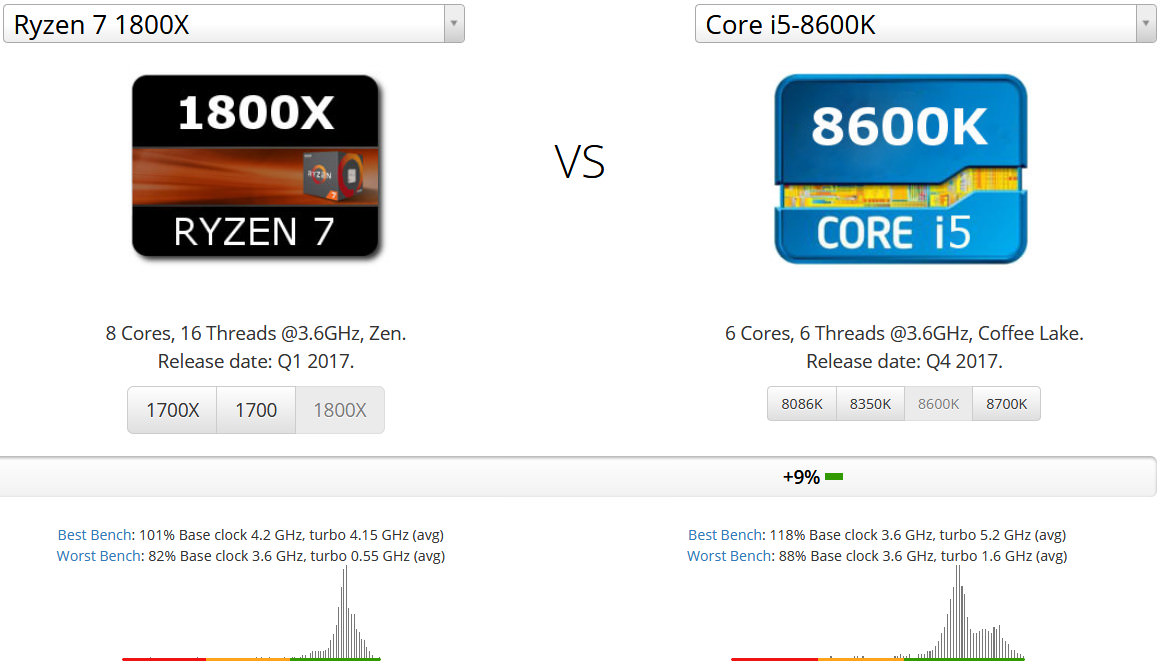
+9%もCore i5 8600Kが勝っています。Core i7 8700K相手だとさらに大きな差がついてしまいます。Ryzen 7 1800Xと他のIntel Coreプロセッサとの比較はこちらにまとめています。
Ryzen 7 1700X
2017年3月発売。Ryzen 7 1700XはRyzen 7 1800Xとの対比で位置づけを捉えることが重要です。半導体チップを作る際、円形のウェーハから切り取ったダイ(チップ)には確率的に優劣が存在します。そのうちクロック周波数を高くできる優秀なダイを使ったのがRyzen 7 1800Xです。一方でクロック周波数が上がらない劣ったダイを使ったのがこのRyzen 7 1700Xです。
ともに8コア16スレッドであり、違いはクロック周波数の高低だけになります。つまり予算があるなら価格以外のすべての面においてRyzen 7 1800XがRyzen 7 1700Xよりも優れています。
ではこのRyzen 7 1700XをIntel Coreと比較してみます。同じ2017年に発売されたCore i7 8700Kと比較します。型番的にはカウンターパートなのですがCore i7 8700Kは6コアであり2コア少ないことと、内蔵グラフィクスをIntel Coreでは搭載しているため内蔵グラフィクスを搭載しないないRyzenより前提条件は不利です。
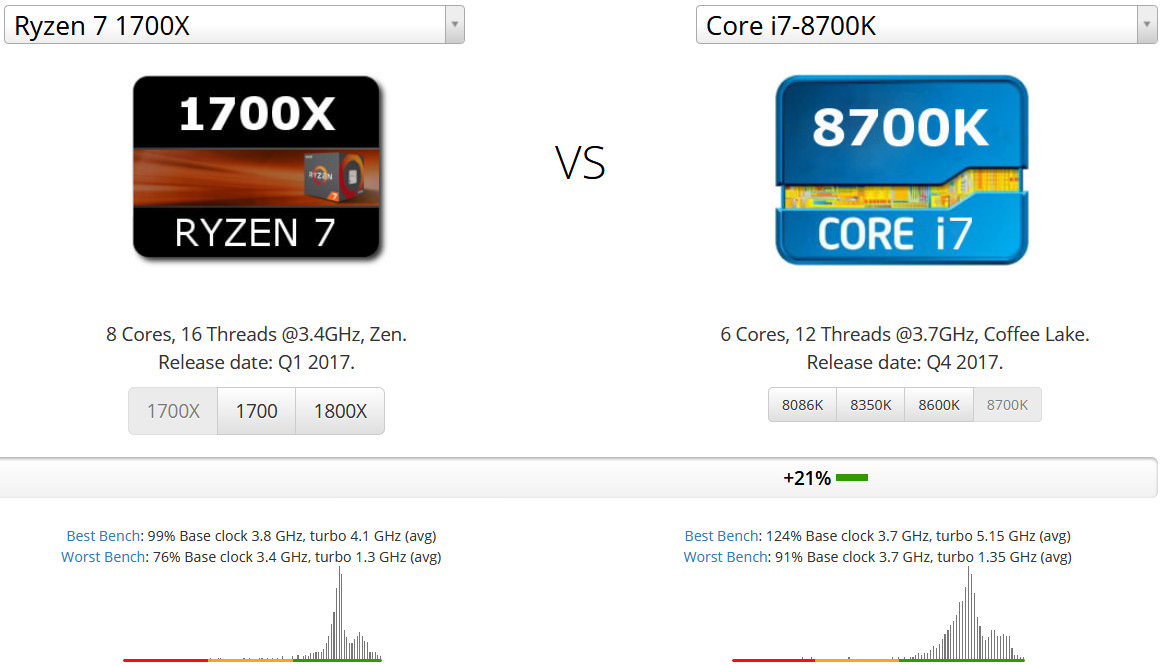
しかしこのように+21%もCore i7 8700KがRyzen 7 1700Xを上回っています。これはCore i7 8700Kのベースクロック周波数が0.4GHz高いことと、マイクロアーキテクチャにおいて第8世代Coffee Lakeが、第1世代RyzenのZenマイクロアーキテクチャより優れており1コアあたりの性能がIntel Coreのほうが高いためです。




Ryzen 7 1700
2017年発売。Ryzen 7 1700X(ベースクロック周波数3.4GHz)からさらにクロック周波数を引き下げて3.0GHzにしたCPUです。そのかわりTDPが65Wになっており低発熱になっています。
第1世代Ryzenではサフィックス(末尾文字)が”X”であっても無印であっても倍率ロックが解除されています。つまり保証外で自由にオーバークロック可能です。
では1700Xとこの1700無印は何が違うかと言うと、1800Xと1700Xとの関係と同じで「1700Xレベルまでクロック周波数が上がらない個体(チップ)を1700として売っている」という関係にあります。つまり1700Xが1700より完全に上位です。ただし消費電力の低さを重視するならTDP65Wの1700ということになりますが、RyzenではTDP65Wとは思えないほど高発熱なのでTDP65WだからといってIntel Coreのようにファンレスにできたりはしません。
同じTDP65Wで2017年発売の第8世代Intel Core i7 8700と比較してみます。コア数はCore i7 8700が6コアで少ないですがベースクロック周波数は8700が+0.2GHz上です。
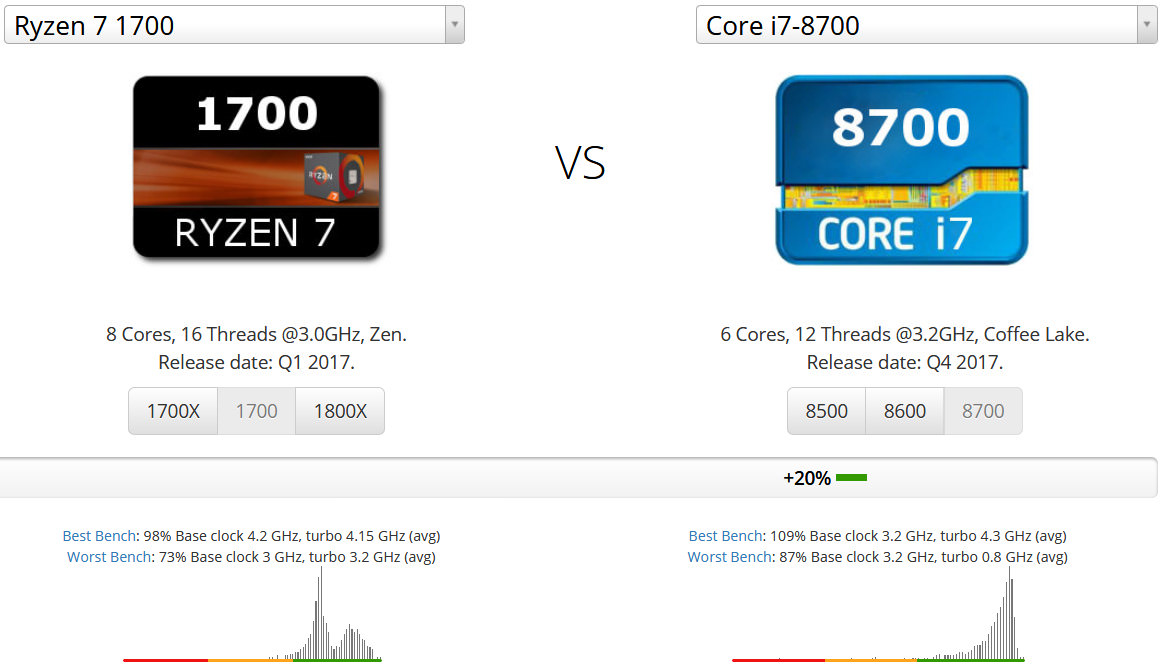
+20%の圧倒的大差でCore i7 8700がRyzen 7 1700を上回る性能になってしまいます。ベースクロック周波数が高いのも要因ですが、マイクロアーキテクチャが第8世代Coffee LakeがZenアーキテクチャより優れているのが最も大きい要因です。
またRyzen 7 1700よりもRyzen 5 1600Xの方が性能が高いです。
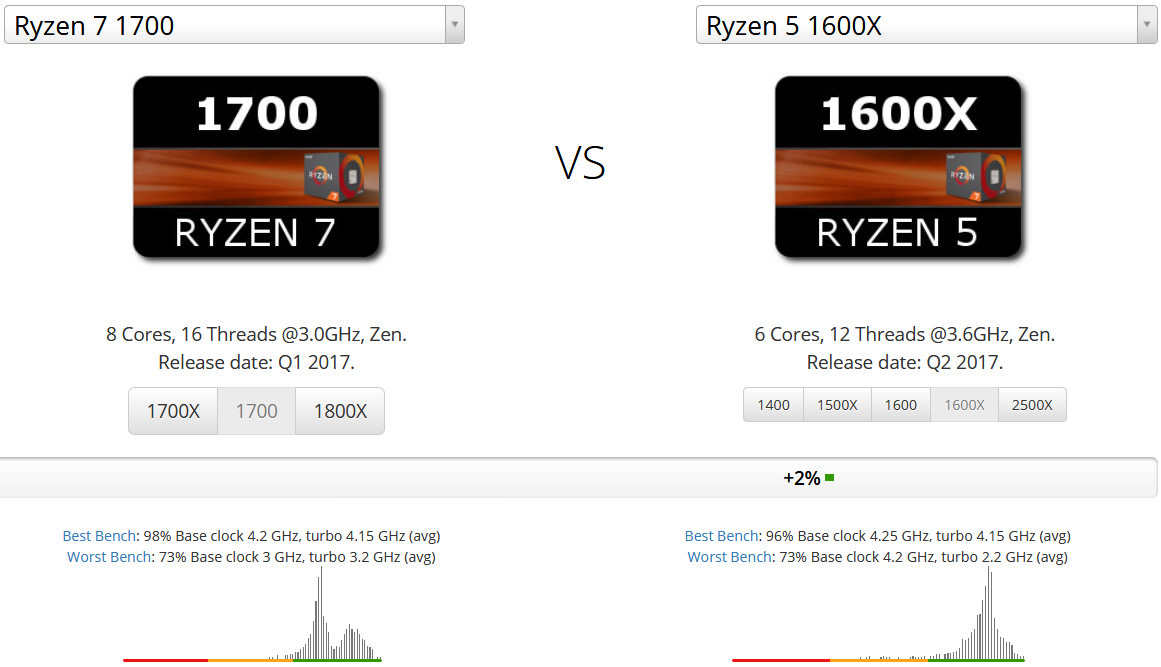
ベースクロック周波数が高い1600Xのほうが1コアあたりの性能が高いために実効性能が高くなっています。コア数といったみかけの数字よりも、実際のパソコン操作の快適性を優先するのならRyzen 5 1600Xの方がおすすめです。




Ryzen 5 1600X
このRyzen 5 1600Xは2017年に発売された6コア12スレッドプロセッサです。これよりも8コア16スレッドのRyzen 7 1700が高速だと思われがちですが実際は逆です。
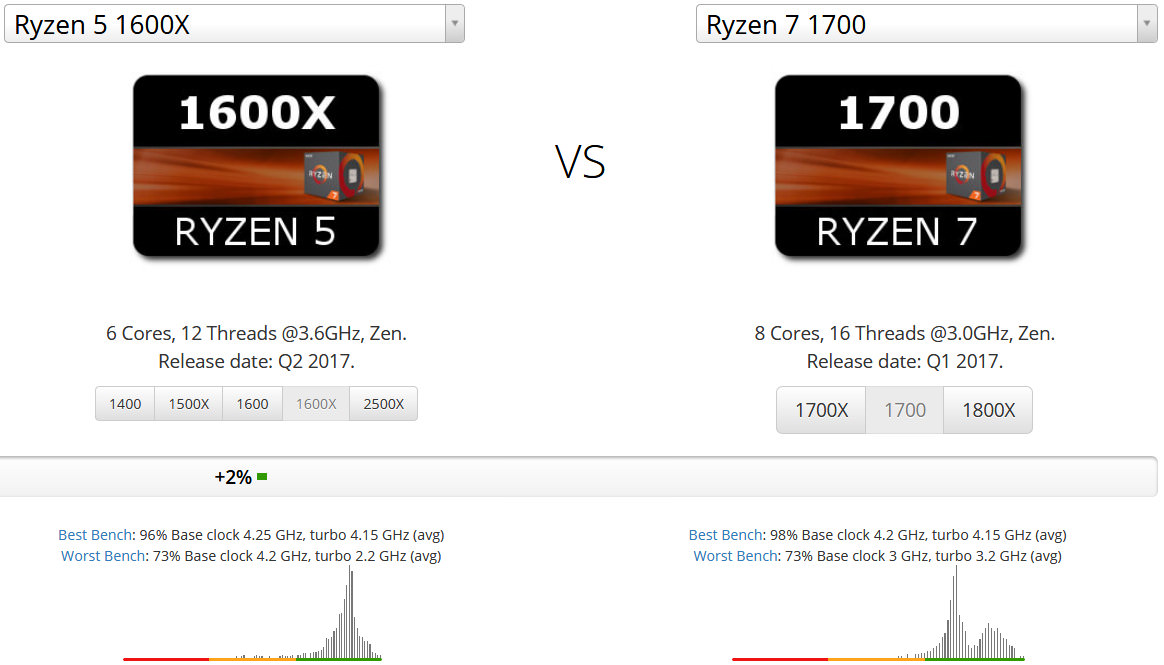
コア数が6しかないながらも+2%、8コアのRyzen 7 1700に勝っています。理由はベースクロック周波数がRyzen 5 1600Xの方が高いからです。コア数ではRyzen 5の方が劣りますが、ベースクロック周波数が高いため1コアあたりの性能はRyzen 5 1600Xの方が上です。マルチコアプロセッサを活用できるアプリケーションは一般用途ではそこまで多くないので、普通に使う分なら1コアあたりの性能が高いRyzen 5 1600Xの方が、1コアあたりの性能が低いRyzen 7 1700に勝つことになります。
そしてこのRyzen 5 1600Xはチップの優秀さという意味ではRyzen 7 1800Xと同等です。第1世代Ryzenの8コアのラインナップでは、1800Xで最も良いチップ(ダイ)を用いて、次が1700X、それより劣ったチップが1700のように振り分けられています。つまりRyzen 7 1700は残り物に近いです。
一方でRyzen 5 1600Xは、Ryzen 7 1800Xで使っている8コアのチップを用いて8コアそれぞれのクロック周波数を引き上げてみて、クロック周波数が上がりにくかったものから順に2つのコアを無効化して6コアにしたものです。そのためベースクロック周波数がRyzen 7 1800Xと同じ3.6GHzになっています。8コアすべてのクロック周波数を高くしなければならないRyzen 7 1800X用のチップよりは下位となりますが、そのうち6つのコアのクロック周波数を高くできることは保証されているためRyzen 5 1600Xはそれなりに優秀な個体を用いたプロセッサです。Ryzen 7 1700XやRyzen 7 1700よりもRyzen 5 1600Xで使用しているチップは優秀です。
Intel Coreとも比較しておきます。同じ2017年に発売された第8世代Core i5 8600Kと比較します。ベースクロック周波数は同じですがCore i5 8600Kは同時マルチスレッディング(ハイパースレッディング)が無効化されています。この点はRyzen 5 1600Xが有利です。またCore i5 8600Kには内蔵グラフィクスが搭載されていますがRyzen 5 1600Xには搭載されていません。この点でもRyzen 5 1600Xが有利です。
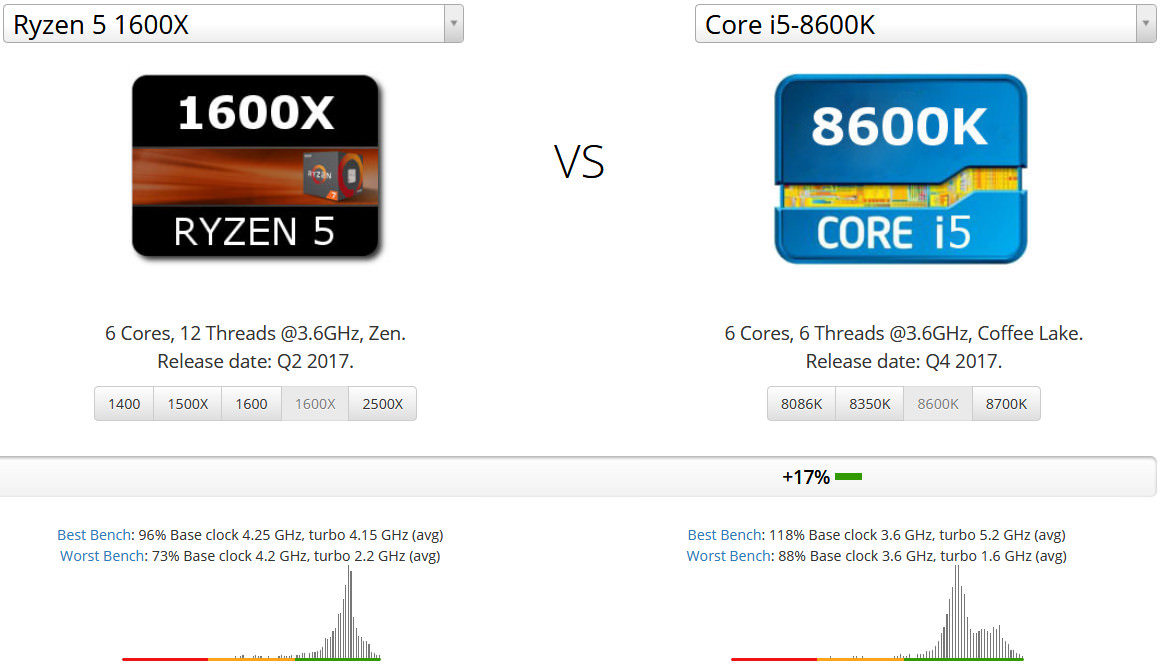
しかし結果はこのように+17%もCore i5 8600KがRyzen 5 1600Xよりも高速です。
またRyzen 7と同じくRyzen 5にも内蔵グラフィクスは付いていないので、内蔵グラフィクスを搭載しつつも汎用コアの性能で勝ってしまったCore i5 8600Kは全面勝利と言えます。






Ryzen 5 1600
2017年発売。Ryzen 5 1600はRyzen 5 1600Xのベースクロック周波数3.6GHzを3.2GHzまで落とし、単位時間あたりの発熱量を低下させたものです。
実際にはRyzen 5 1600Xとして売るためのクロック周波数まで上がらなかった質の低い個体(チップ)を、正常に動作するクロック周波数まで落としたものとして売られているのがRyzen 5 1600です。
同じ2017年に発売されたCore i5 8600と比較してみます。両者の違いはベースクロック周波数に関してはRyzen 5 1600のほうが+0.1GHz高く有利です。またCore i5 8600は同時マルチスレッディング(ハイパースレッディング)が無効化されているためこの観点からもRyzen 5 1600が有利です。さらにCore i5 8600ではチップ上に内蔵グラフィクスが搭載されいるため、チップに内蔵グラフィクスを搭載していないRyzen 5 1600のほうが有利です。
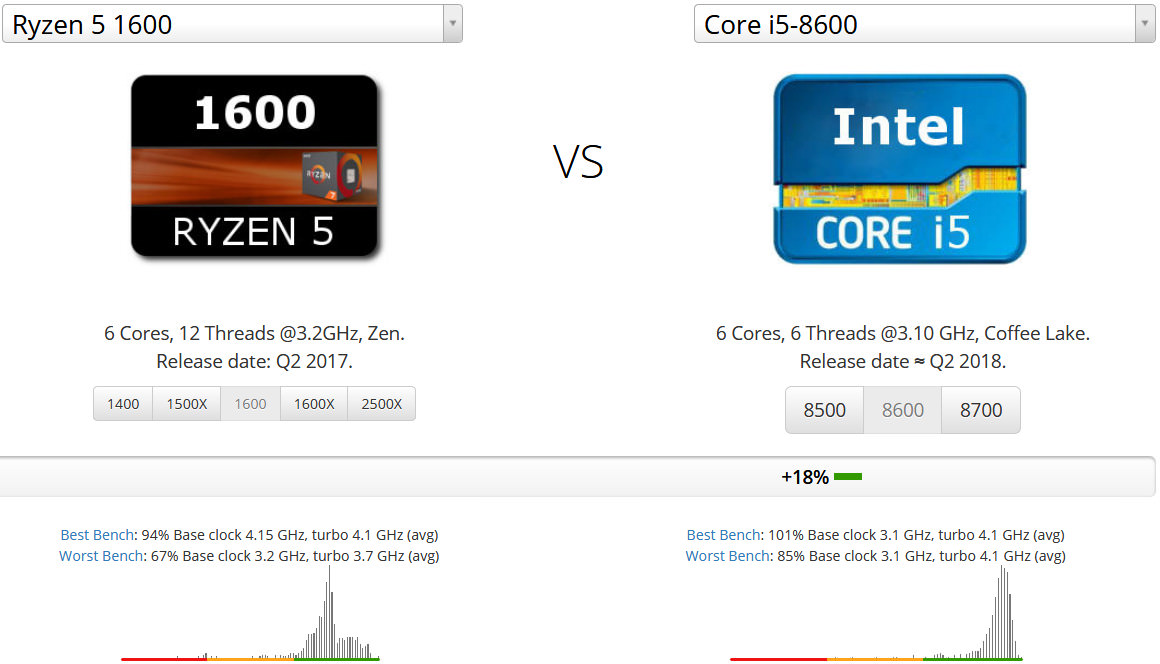
結果はCore i5 8600が+16%もRyzen 5 1600に勝利しており、圧倒的不利な前提条件でもここまでの大差がついてしまいました。この差はクロック周波数では説明できません。クロック周波数はCore i5 8600のほうが低いからです。この差はRyzen 5 1600では3コアで1つのL3共有キャッシュを持っており、3コアと3コアで2ブロックに分割されてしまっているため、せっかく片方のL3共有キャッシュに載っているデータであってももう片方のL3共有キャッシュには存在せずキャッシュミスとなってしまい、このキャッシュミスペナルティが大きすぎるためです。またSIMD演算器の性能がIntel Core i5 8600はRyzen 5 1600の2倍(+100%)の性能があることにも起因しています。








Ryzen 5 1500X
2017年発売。6コアRyzen 5 1600Xのコア数をさらに追加で2コア分無効化したものです。
Ryzenで採用されたZenアーキテクチャでは、4コアとL3共有キャッシュで一つの構成要素になっておりこれをCCXとAMDは呼んでいます。このCCXが1枚のチップに2基存在するため、合計8コアを実現しているのがRyzenです。
そしてこのRyzen 5 1500Xは、CCXに存在する4コアのうち2コアを無効化しています。そうすると2基のCCXで4コアになります。
なぜわざわざコアを無効化してしまうかというと、すべてのコアが等しく性能が高いとは限らないからです。半導体の製造上はどうしても確率的に正常に動作しない部分がでてきてしまいます。そこでクロック周波数がなかなか上がらない質の低いコアを無効化して、クロック周波数を上げても正常に動作するコアだけを残すようにします。そうすれば本来不良品として捨ててしまうはずのチップを売り物として出すことができます。それがRyzen 5 1500Xです。
このRyzen 5 1500XをIntel Coreと比較してみます。同じ2017年発売の第8世代Intel Coreと比較します。しかしこのRyzen 5 1500Xに相当するCore i5 8500Kのようなプロセッサは存在しません。かといってCore i5 8600Kと比較してしまうと、グレードが上のIntel Core側に有利になりすぎてしまいます。
そこでCore i3 8350Kと比較してみます。同じ4コアですし、Ryzen 5と本来比較すべきCore i5より下位のCore i3と比較するならRyzen側にとって不利な前提条件にはならないからです。

しかし結果はIntel Core i3 8350KがRyzen 5 1500Xに+22%も勝利しています。まずCore i3 8350Kの勝因は主に2つあります。1つはクロック周波数が4.0GHzであり、Ryzen 5 1500Xの3.5GHzよりも大幅に高いことです。
もう一つの勝因は、Intel Coreのマイクロアーキテクチャが優秀であることです。アウトオブオーダー実行とスーパースカラを組み合わせた命令レベル並列処理における並列性抽出度が優れていること、SIMD演算器が充実しており少ないサイクル数で一度に複数のデータに対して演算を施すことができること、パイプラインで命令をスムーズに流しスループットを向上させるため分岐予測やキャッシュ機構が優秀であることがマイクロアーキテクチャが優秀な理由として挙げられます。つまり技術的にIntelの方が優秀だということです。しかも内蔵グラフィクスのIntel HD Graphicsもついてくるのですから、Intel Core i3 8350Kはかなり優秀なプロセッサに仕上がっています。ただし一つ弱点があり、それはCore i3 8350KのほうがRyzen 5 1500Xより高額だということです。価格の安さを重視したい場合はRyzenがいいでしょう。








Ryzen 5 1400
2017年度発売。第1世代で採用された8コアのチップのうち4コア分を無効化したCPUです。
Ryzenプロセッサは1枚のチップ(ダイ)に2基のCCXというブロックが存在します。CCXの定義は「L3共有キャッシュを共有するコアの集合」です。CCXは4コアあるため、CCXが2基で合計8コアを実現しているのがRyzenです。
このRyzen 5 1400はその8コアのうち4コア分を無効化したものですが、それは片方のCCXを全て無効化したものではありません。
片方のCCXに存在する4コアのうち2コア分を無効化し、もう片方のCCXに存在する4コアのうち2コア分を無効化して、合計4コアのプロセッサに仕上げています。
なぜあえてコアを無効化するのかと言えば良品率(歩留まり)を向上させて、不良品として捨てずに売れるようにするためです。例えば8コアのうち4コア分が正常に動作しなくてもそれらを無効化すれば残り4コアが正常に動作するものとして販売できます。それがRyzen 5 1400です。
また正常に動作するコアが8コアあったとしても、クロック周波数がほとんど上がらないコアが確率的に発生してしまいます。そこでCCXに存在する4コアのうちクロック周波数が上がらないコアから順に2コアだけ無効化します。そのようにすることで、クロック周波数が上がらないコアが存在したとしても、クロック周波数が上がるコアだけ残して売り物とすることができます。
このRyzen 5 1400は2017年度に発売されたものなので同じ2017年度発売のCore i3 8100と比較してみます。Core i3 8100では同時マルチスレッディング(ハイパースレッディング)が無効化されているためその点はRyzen 5 1400に有利です。一方でクロック周波数はRyzen 5 1400が3.2GHzで、Core i3 8100が3.6GHz一見Ryzen 5 1400側に不利に見えます。しかしCore i3 8100はTurboBoostが無効化されているためクロック周波数3.6GHzで一定です。その点Ryzen 5 1400はブーストクロック周波数3.4GHzまで届くので差はそこまで大きくありません。また型番をみてもわかる通りRyzen 5とCore i3なので、カタログスペックだけをみれば明らかにCore i3が不利です。
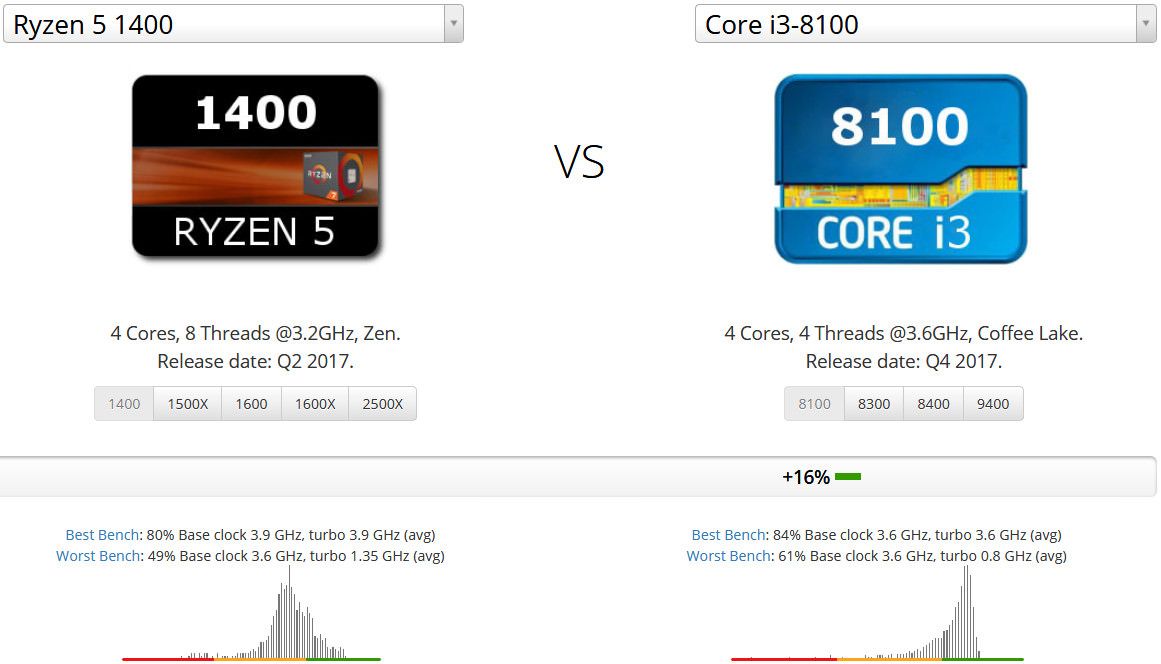
しかし結果はCore i3 8100がRyzen 5 1400に+16%も勝ってしまいます。Ryzen 5 1400の主な敗因はL3共有キャッシュです。Ryzen 5 1400は8つのコアのうち4つを無効化して4コアにする際に、1つのCCXを丸ごと無効化するのではなく、各CCXそれぞれで2コアずつ無効化しています。
つまりRyzen 5 1400は2コアで1つのL3共有キャッシュを持っていることになります。つまりCCX0に属するコア0とコア1と、CCX1に属するコア2とコア3の4つのコアで見た場合、コア0に割当てられていたスレッドがアクセスしていたデータがCCX0のキャッシュに存在しても、そのスレッドがOSによってコア3に割当てられてしまうとCCX1のキャッシュにはデータが存在しないため”キャッシュミス”となってしまいます。このキャッシュミスの頻発によるキャッシュミスペナルティがパイプラインをスムーズに流してIPCを向上させることを妨げており、Intel Coreと比較してなかなか1コアあたりの性能が上がらない主因です。しかもCore i3 8100には内蔵グラフィクスも搭載されているのでCore i3 8100がおすすめです。




Ryzen 3 1300X
2017年度発売。Ryzen 5 1400と同じ4コアですが同時マルチスレッディングが無効化されているため4コア4スレッドになっています。そのかわりクロック周波数はRyzen 5 1400より引き上げられています。そのため末尾文字(suffix)が”X”になっている高クロックモデルになっています。
これは意外と優秀なCPUです。Ryzen 5 1600を買うならこのRyzen 3 1300Xがいいでしょう。なぜならこのRyzen 3 1300Xの動作周波数は3.5GHz~3.7GHzもあり、2017年度に発売された第1世代Ryzenシリーズの中でもトップクラスの高さです。コア数は4コア4スレッドであり決してコア数は多くありませんが、このことが逆に功を奏しています。コア数を4コアに抑えてクロック周波数を上げたことにより、1コアあたりの性能が重要であるほとんどのアプリケーションが恩恵を受けることができるため性能が高くなっています。下手にRyzen 5を買うよりこちらの方が望ましいです。クロック周波数が高く、動画エンコードのような並列性の高い用途以外でも性能が出るようになっているCPUです。
同じ2017年度に発売されたCore i3 8350Kと比較してみます。ともに同時マルチスレッディングが無効化された4コア4スレッドのプロセッサです。クロック周波数はCore i3 8350Kが4.0GHzもありますが、Core i3 8350KはTurboBoostが無効化されているため定格動作ではこの4.0GHzからクロック周波数が上がることはありません。一方でRyzen 3 1300Xは最大で3.7GHzまでクロック周波数が上がるためそこまでRyzen 3のクロック周波数が低いわけではありません。
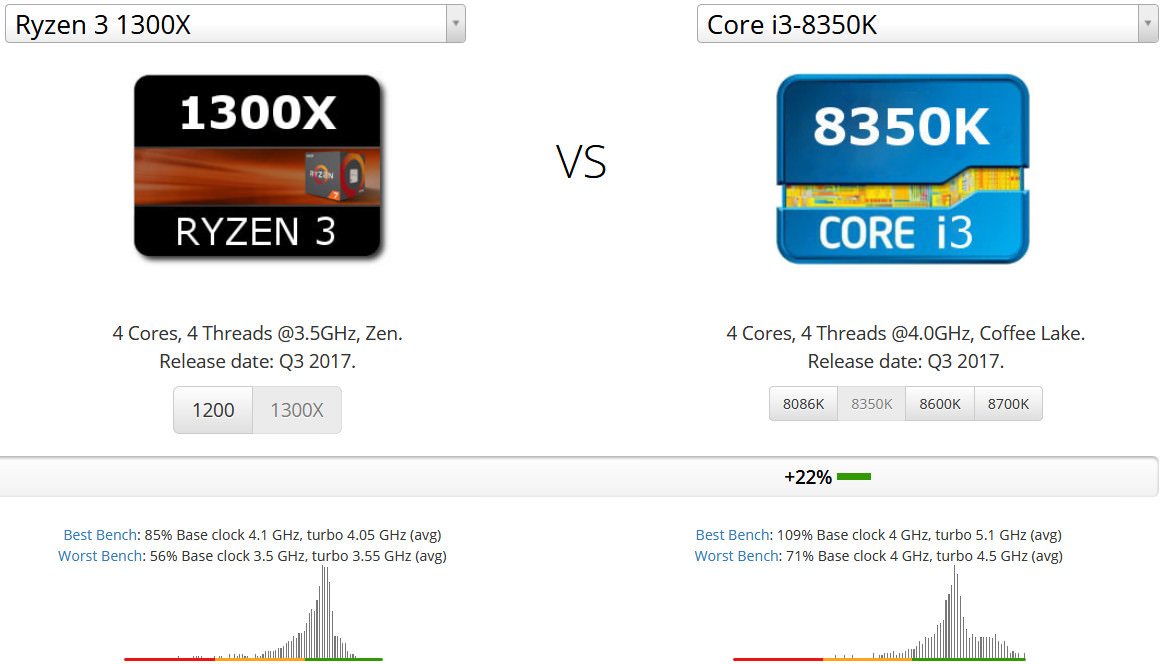
結果は+22%もCore i3 8350KがRyzen 3 1300Xを上回ります。かなりの圧倒的な差です。これはクロック周波数だけの差だけでは説明がつかない性能差です。Ryzen 3 1300Xは同じ4コアプロセッサですが、2コア+2コアの構成になっておりL3キャッシュが共有されていません。一方でCore i3 8350Kは4コアでL3キャッシュを共有しておりキャッシュヒット率が高いです。これがこの性能差につながっています。




Ryzen 3 1200
2017年7月発売。Ryzen 3 1300Xのベースクロック周波数3.5GHzからさらにクロック周波数を引き下げたものです。つまりRyzen 3 1300Xとして売るほどまでクロック周波数が上がらなかった不適合品を、正常動作するレベルまでクロック周波数を引き下げて売っているのがこのRyzen 3 1200です。クロック周波数を引き下げているのでRyzen 3 1300Xより低消費電力になっています。
同じ2017年度に発売された第8世代Intel Core i3 8100と比較してみます。Intel Coreには8200といった型番が存在しないため、Intel Coreプロセッサの中で最も低性能なCore i3 8100と比較する分にはRyzen 3 1200にとっては不利にならないので、あえて型番が下のCore i3 8100と比較してみます。
同時マルチスレッディング非対応であることは、Ryzen 3 1200でもCore i3 8100でも共通です。ベースクロック周波数はRyzen 3 1200が3.1GHz、Core i3 8100が3.6GHzでありCore i3が有利です。しかしRyzen 3 1200はブーストクロック周波数が最大3.4GHzまで上昇します。Core i3 8100はTurboBoost非対応なので3.6GHz固定です。なのでクロック周波数にはそこまで優劣は存在しません。
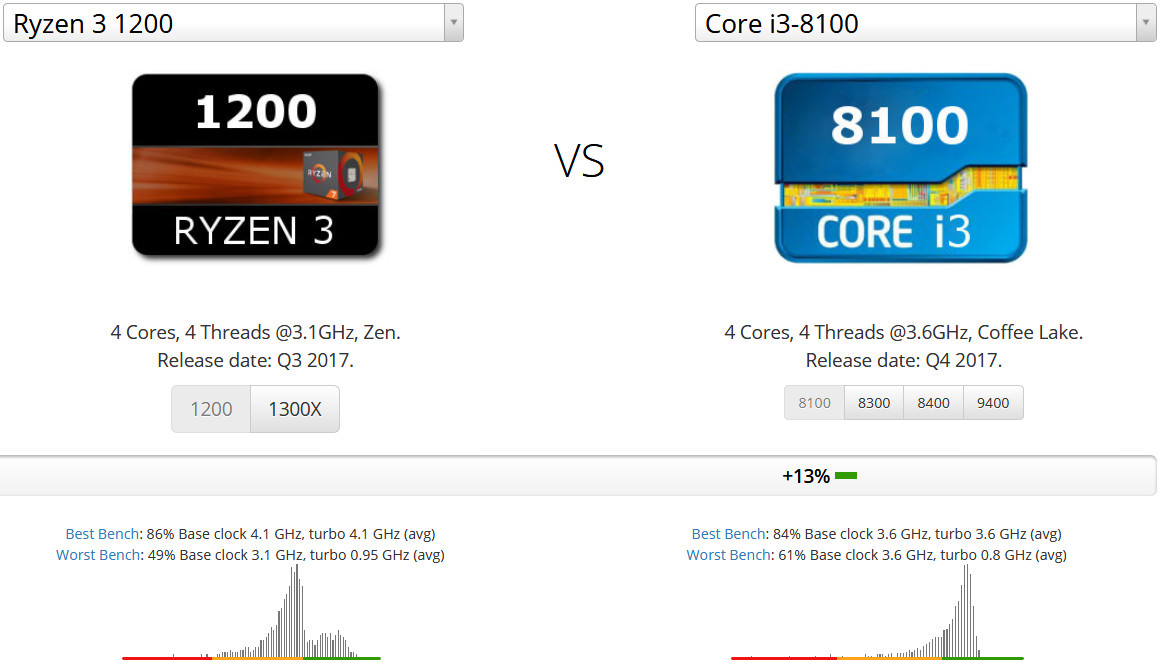
結果は+13%もCore i3 8100がRyzen 3 1200の性能を上回っています。しかもこのTDP65WのRyzen 3やCore i3のような低消費電力CPUを購入するユーザー層はゲーム用ではなく事務作業用を想定している場合が多いので、内蔵グラフィクスを搭載しているCore i3 8100になおさら軍配が上がります。








Ryzen 5 2400G
2018年2月13日発売。オンボードグラフィクス(内蔵グラフィクス)をCPUチップ上に搭載したAMD APUです。内蔵グラフィクスをRyzenでも搭載したことによって、Intel Coreと対等に比較できるようになったRyzenプロセッサです。第1世代のRyzen 1000シリーズ(Summit Ridge)プロセッサは内蔵グラフィクスを搭載せずに、その空いたチップ面積を汎用コアに割り当てていたため、内蔵グラフィクスをCPU上に搭載したことによって汎用コア用のチップ面積が限られているIntel Core側にハンデがありました。そのハンデがありながらもIntel Coreは、第1世代Ryzenプロセッサに勝利していたわけですが、今回の第2世代Ryzen Gでは内蔵グラフィクスが搭載されたので、これでようやくIntel Coreと対等に比較できるようになります。
しかし第1世代Ryzen 1000シリーズでは内蔵グラフィクス無しというRyzen側に有利だったにもかかわらず、第1世代Ryzen(Summit Ridge)はIntel Coreに性能で大幅に負けていたので、今回の第2世代Ryzen Gプロセッサは内蔵グラフィクスを搭載してしまったことにより、内蔵グラフィクスを搭載していない第1世代Ryzenよりもさらに不利になっています。
同じ4コア同士のプロセッサで比較してみます。2018年に発売された第2世代Ryzen Gは同じく2018年に発売された第9世代Intel Coreと比較すべきものですが、第2世代Ryzen Gで採用されているマイクロアーキテクチャはZen世代であり中身は第1世代Ryzenプロセッサです。そこで第1世代Ryzenプロセッサが発売された2017年と同じ年に発売された第8世代Intel Coreプロセッサと比較してみます。
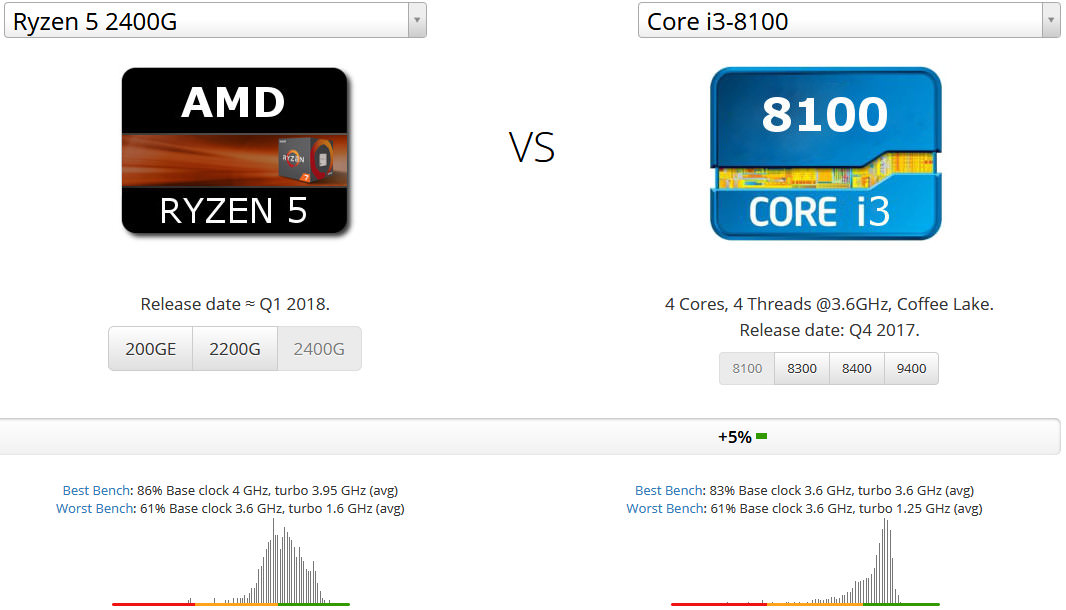
このようにIntel第8世代CoffeeLake Coreプロセッサの最低スペックモデルであるCore i3 8100にすら負けています。+5%もCore i3 8100の方が上です。詳しくはこちらに掲載しています。






Ryzen 3 2200G
2018年2月13日発売。動作周波数は3.5GHzで4コアであり、多コア化がアイデンティティのRyzenにしては大人しいコア数です。これはAPUというオンボードグラフィクスを搭載したCPUであり、汎用コアに割り当てることのできるチップ面積が減ったためです。
PUBGというゲームではRyzenのコア数を使いこなすだけの並列性がなく、Ryzenはゲーム用途にもかかわらず各PCメーカーのPUBGモデルはIntel Core i7を採用するという憂き目にあっていました。
そのためか第2世代のRyzenは1コアあたりの性能を重視しているようです。第1世代のRyzenは高々3.7GHzの動作周波数しかありませんでしたが、第2世代ではRyzen 3ですら3.5GHzになっています。しかし1コアあたりの性能ではIntelに勝つのは難しいでしょう。ソフトウェア(アプリケーション)の並列性を前提として、1コアあたりの性能でまけてもコア数では負けないという方向性だったRyzenは第2世代ではIntel Coreと同じコア数になってしまったため差異を出せず苦戦しています。

このようにCore i3 8100に負けています。Ryzen 3 2200Gよりも+8%もCore i3 8100が勝利しています。本来ならばRyzen 3 2200Gと比較すべきはCore i3 8200ですが、Core i3 8200は発売予定がないため、より低スペックなCore i3 8100と比較する分にはRyzen 3 2200Gが有利になるだけなので問題ないでしょう。
このようにRyzen 3 2200Gにとって有利な条件で比較してもこの結果ですし、実際に2018年2月13日の発売日から一週間程度は注目されていましたが2018年3月になってからRyzen G熱は相当下火になってきています。


第1世代Ryzenで採用されたZenアーキテクチャの敗因:
SIMD演算器(FMA)が8flops/サイクルしかなくIntel Coreの半分
さらにL3キャッシュのレイテンシが35cycleもありパイプラインのストールが多発でIPC大幅低下
2017年3月に発売された第1世代RyzenではZenアーキテクチャが採用されています。このZenアーキテクチャの敗因を見ていけば、Zenアーキテクチャを元に製品化された第1世代Ryzenの敗因が見えてきます。
128bit幅のSIMD演算器(FMA)を2基しか搭載していない
SIMD演算器というと馴染みがないかもしれませんが、AVXやSSEといえば聞いたことのある人は多いと思います。SIMDとは1つの命令で複数のデータに同時に演算を施すことで、「1命令あたりの演算数を増やす」「1サイクルあたりの演算数を増やす」というHPC(ハイパフォーマンスコンピューティング)の高速化手法の一つです。1つの命令で1つのデータにしか演算できないとなるとFLOPS(1秒間あたりに実行する小数演算の回数)を向上できません。そこで1つの命令で同時に複数のデータに演算を施せば高速化できるということでSIMDが登場しました。
a=b+cのような通常の加算命令はSISD(Single Instruction Single Data)に分類されます。またスーパースカラによる命令レベル並列処理や、パイプラインによるスループット向上もSISDの分類です。
そしてMIMD(Multiple Instruction Multiple Data)はIntel CoreやRyzenで採用されているような「マルチコアプロセッシング」が該当します。それぞれのコアで複数の命令ストリーム(スレッド)が走り、それぞれのスレッドがそれぞれのデータに対して処理を施すのでMIMDです。
SIMDはその中間と位置づけられます。SIMDは1コアで実行される1つの命令で複数のデータに対して同時に演算を施すためです。
結論から言うと、Zenアーキテクチャ(第1世代Ryzen)のSIMD演算性能は64bit倍精度小数で8FLOPS/cycle、32bit単精度小数で16FLOPS/cycleしかありません。
一方でIntel Coreは64bit倍精度小数で16FLOPS/cycle、32bit単精度小数で32FLOPS/cycleもあります。実にRyzenの2倍(+100%)の性能です。
このようにZenアーキテクチャのSIMD演算器がIntelに完敗してしまったのは、FMA命令仕様の覇権争いがあります。FMA命令とは積和命令のことで、小数同士の掛け算を行った後に加算(足し込む:Accumulate)を1サイクルで一度に行ってしまうものです。
IntelはFMA3命令にこだわり、一方でAMDはFMA4命令にこだわったことで仕様が統一されていませんでした。これでは同じx86命令セットアーキテクチャにも関わらず、2つのFMA命令規格が混在するのかと思われていたところ、AMDが敗北宣言をしZenアーキテクチャからFMA4命令を取り下げることになりました。これによりFMA命令はIntelのFMA3命令に統一されることになりました。この敗北宣言がZenアーキテクチャでSIMDが微妙になる要因となってしまったわけです。
Zenアーキテクチャでは128bit幅のFMAを2基搭載しており、128bitで4FLOPS/cycleの小数演算が可能です。演算器2基に加えて、FMAは積和を1サイクルで実行するため「積」「和」の2つのオペレーションがあるため2×2で4FLOPS/cycleになるためです。そして128bit幅あるため、64bit倍精度小数(double型)なら8FLOPS/cycle、32bit単精度小数(single型)なら16FLOPS/cycleとなります。
一方でIntel Coreは256bitの演算器を2器搭載しており、Zenアーキテクチャの2倍のビット幅があります。そのため倍精度で16FLOPS/cycle、単精度で32FLOPS/cycleという2倍の性能になっています。
L3キャッシュがヒットしてもレイテンシが非常に大きい
AMD RyzenでもIntel CoreでもL1とL2キャッシュについてはレイテンシはそれぞれ4サイクル、12サイクルと同じになっています。
差があるのがL3キャッシュです。Intel CoreではL3キャッシュレイテンシを25サイクル以下に抑えていますが、Ryzenは35サイクル以下です。
実はZen2アーキテクチャではこれが40サイクル以下と改悪されました。
L3キャッシュのレイテンシが大きいとパイプラインのストールが深刻化します。35サイクルもパイプラインが停止し、その間後続の命令を流すことができません。せっかく後ろの命令はL1キャッシュにヒットするからスムーズにパイプラインを流せるにもかかわらず、先行の命令がL2キャッシュミスとなってしまったことで非常に大きなペナルティを被ることになってしまっているわけです。
L3キャッシュミス時のペナルティが数100クロックもある
第1世代RyzenのL3共有キャッシュは4コアあたり8MBしかありません。メモリは16GB~64GBもあるため、8MB程度のキャッシュではL3キャッシュミスは何度も発生します。しかしそれはIntel Coreも同じであり、Intel CoreもL3キャッシュサイズもそこまで大きくありません。
問題はL3キャッシュミスとなったときのレイテンシの大きさです。
Intel Coreの場合はL3キャッシュサイズを超えたデータアクセスをしてもレイテンシが30サイクル、50サイクルとデータサイズに比例して徐々に上がっていくだけなのですが、Ryzenの場合はL3キャッシュサイズを超えた途端一気に数100サイクルまでペナルティが上昇してしまいます。
この間、パイプラインは数100サイクルも停止させられることになってしまいます。これがRyzenの1コアあたりの性能が低い主要因です。